

Natural Language Processing
Generating paraphrases
Generating paraphrases

TRURL brings additional support for specialized analytical tasks:
Dialog structure aggregation
Customer support quality control
Sales intelligence and assistance
TRURL can also be implemented effectively on-premise:
We will build a GPT model for you
Trained securely on your infrastructure
Trained on your dataset

Share
Data is the key ingredient in Machine Learning, which is based on learning from it. The Deep Learning field is even more data hungry, due to large models, that need to generalize well and avoid overfitting to the training data. In most Machine Learning problems like Speech Recognition getting large amounts of labelled data is very expensive and time-consuming. This was discussed in a previous blog post on self-supervised trend in Speech Recognition (link). The self-supervised paradigm is pretty recent, but very promising method used in Speech Recognition (link). Another method, that was used even before the Deep Learning era is Pseudo Labelling (link, link, link, link). This is a Semi-Supervised learning paradigm, which uses model’s own output labels to train itself.
The standard procedure is to predict the labels for the unlabelled data and filter those, which prediction probability is pretty low. This should leave only examples, which in most cases are correctly labelled. How well this technique works is highly dependent on the models quality and how trustworthy are the probabilities. For tasks, where the output is not a single label, but a sequence such as Speech Recognition there is another problem, which is how to handle examples, when part of it is pretty confidently recognized and part has much worse probability. An example could be a single-channel agent-client phone conversation, where client’s speech is often of much worse quality. It is important to notice, that the agent’s voice has much better quality, but the client’s is adding much more to the speaker and domain variability. To improve the filtering quality the pseudo labels could be checked for some model specific errors (link). During the process the hard examples are being filtered-out. Similiar to supervised training to make the data more useful the model need to be disrupted with some regularizations, like dropout, or data need to be augmented with noise or SpecAugment (link, link) to get more out of it.
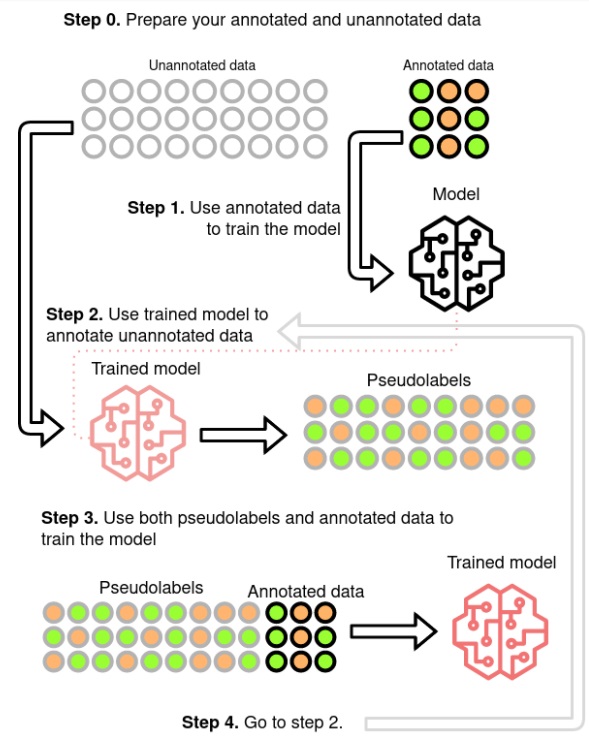
Pseudo-labeling method (source)
Having improved the model in a Pseudo Labelled setup the question that arises is if the model, being learned on the unlabelled data, could create a better pseudo labels for it, than the fully supervised one. This was explored in (link) as Iterative Pseudo Labelling and in (link) as Noisy Student Training. Both state that data augmentation, beam-search decoding with an external Language Model (LM) and balance between the labelled and unlabelled sets are the keys for good performance. (link) uses also filtering mechanism, which probably leads to the better results. In both approaches the beam-search decoding and the external LM are the most problematic components. Beam search, because it is computationally expensive, limiting the number of iterations. External LM, because it is biasing the Acoustic Model (AM) (link). (link) proposes Language-Model-Free IPL (slimIPL) rejecting the beam-search and LM, by using the most probable AM outputs combined with a dynamic cache. Using the dynamic cache enables part of the unlabelled examples to be processed again in a short period with the same pseudo labels and it was shown that this greatly increases the stability of the training, especially for experiments with small labelled sets. The instability is most often caused by model pushing itself into outputting ever less labels. Having generated labels only for a part of the true labels, it is encouraged through learning on them to omit even more. Dynamic cache probably by showing the same example again with more labels than the current model would generate is stopping the model from taking that path. There were proposed alternative approaches to stabilize the training using exponential moving average (EMA) (link, link). One of them was even shown to effectively combine with the dynamic caching.
Most of the articles’ experiments are performed on the Librispeech dataset (link), sometimes adding LibriLight (link) for large scale experiments. The dataset consists of audiobook recordings read by voluntary speakers. This gives often not very high quality audio and lot of accents, but they are single speaker recordings of rather static intonation and speed, containing little emotions and background noises. With current SOTA Speech Recognition models (link) it is possible to achieve 1.9% WER for clean and 3.9% for other test sets without any unsupervised or semi-supervised approaches. This brings doubt if the semi-supervised methods could perform well on real-life data. (link) tests the slimIPL on Conversational Telephone data, but those popular sets (Switchboard (link), Fisher (link, link)) can be classified as single source (single domain). Combining multiple models it is possible to achieve even 5% WER on the corresponding test set, which is not achievable on real-world telephone data (link) (the authors stated on Interspeech 2017 presentation that real-world data had ~20% WER on this model). (link) uses public videos as training data for English and Italian. It is hard to judge the quality of the data, but the semi-supervised approach gives almost same results using only 10h of labelled data and 75kh of unlabelled compared to 650h labelled data in supervised training, which makes the acoustic models creation much faster and cheaper. So it is not exactly clear how the Pseudo Labelling would perform if the labelled data would be of much different acoustic domain than the unlabelled or if the unlabelled would come from lots of acoustic domains.
In our Pseudo Labeling experiments we used modified version of Performance Monitoring (link) to filter out the audio files that are predicted to have worse WER than a threshold. It is working well for high quality audio like data from media. The correlation between predicted WER and real WER is pretty good, but when used for lower quality 8kHz telephone data the WER correlation is not good enough. Experiments with such data show, that the resulting model is performing worse than a model on labeled data only.
Inferring from our experiments and from articles one can state, that the Pseudo Labeling approach is working well if the data is of high quality and the model can predict labels with pretty high accuracy. If the quality of the audio is lower and even the human error is pretty high, the recognitions will give lots of errors, so for some corpora the pseudo-labelled data can bring more harm than good. The second argument against using it for telephone data is the data augmentation. As for SpecAugment it can be accepted that it does not shift the domain of the data, but adding noise could be seen as such shift. So the best way to improve for such data would be augmenting a better quality to an approximation of the telephone quality, but such a domain shift is a separate research area by itself.
In comparison to Self-Supervised learning Pseudo Labelling seems to be less computationally expensive (slimIPL’s 83.2 vs Wav2Vec2.0’s (link) 294.4 GPU-days)(link), but if working on multiple languages probably this would shift on the other side, because of easier reusability of the pre-trained Self-Supervised model. A great news is that the slimIPL can be combined with models like Wav2Vec2.0 and adds additional value on top of them (link, link). As for the multilingual usage a procedure was proposed (link), but compared to Self-Supervised training it is a pretty complex one.
So the Pseudo Labelling approach is best suited if one stays in a relatively closed domain and has lots of real-life data of decent quality. The good thing is that it could be setup in a self-learning mlops manner, that is continuously improving by combining the available labelled data with new incomming production data. This should improve the model both generally, but especially for the new domains that will appear. To enhance the process part of the most difficult filtered-out examples could be sent to the human-in-the-loop and come back as labelled data improving also for the worst quality data.
Share
Author: Jakub Kaliski

