


VOICELAB.AI Sp. z o. o. realizuje projekt dofinansowany z Funduszy Europejskich „Stworzenie multimodalnej i wielojęzycznej platformy do automatycznej replikacji komunikacji między ludźmi, pozwalającej na modelowanie zachowań komunikacyjnych pomiędzy człowiekiem a maszyną”
Tytuł projektu
Stworzenie multimodalnej i wielojęzycznej platformy do automatycznej replikacji komunikacji między ludźmi, pozwalającej na modelowanie zachowań komunikacyjnych pomiędzy człowiekiem a maszyną.
Streszczenie projektu
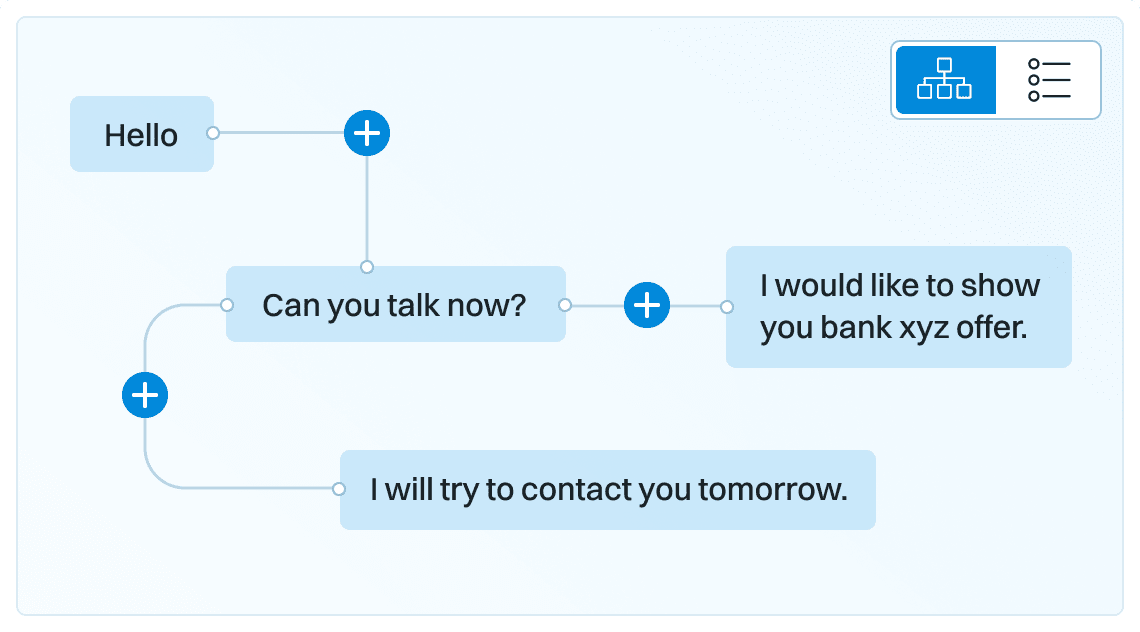
Opracowana w projekcie platforma będzie służyć do tworzenia nowej generacji systemów dialogowych w oparciu o zaimportowane przykłady zachowań komunikacyjnych ludzi, które zostaną automatycznie przeanalizowane z wykorzystaniem automatycznej transkrypcji mowy; automatycznej kategoryzacji; definiowania i identyfikacji pragmatycznych znaczników dyskursu, formuł uprzejmościowych, symulowania zachowań, inferencji gramatyki, a następnie podzielone na zestaw kroków (intencji i akcji) i zamodelowane na struktury grafowe, zarówno w warstwie struktur danych jak też na poziomie graficznego interfejsu użytkownika. Na podstawie takiej reprezentacji danych system będzie automatycznie generował modele zachowań komunikacyjnych odwzorowujące analogiczne zachowania komunikacyjne, jakie występowały w zaimportowanych kontekstach. Modele te będą mogły podlegać ręcznej modyfikacji w celu ich lepszego dopasowania z wykorzystaniem graficznego interfejsu. Platforma zostanie wyposażona w bogate narzędzia umożliwiające testowanie i weryfikacje działania systemu poprzez budowę predefiniowanych modeli i słowników które będą stanowiły bazą testowa dla pojedynczych elementów systemu jak i dla wszechstronnego testowania całego procesu. Testowanie i wskazywanie słabo zamodelowanych elementów systemu jest jednym z bardziej istotnych i trudnych części systemu. Ich właściwa implementacja pozwoli na budowę elastycznych, naturalnych a przede wszystkim efektywnych modeli zachowań komunikacyjnych. Poza algorytmami uczenia maszynowego, skuteczność działania systemu zapewnią duże ilości danych treningowych, domenowych. nagrań i transkrypcji interakcji ludzi, pozyskane wg. metodyki uczenia aktywnego. Innowacyjnym aspektem projektu będzie zwiększenie płynności i elastyczności interakcji poprzez użycie pragmatycznych modeli dialogowych, inspirowanych badaniami na naturalnie występujących danych konwersacyjnych.
Okres realizacji
Od: 2020-03-01
Do: 2023-06-30
Liczba miesięcy: 40
Wydatki projektu
Wartość projektu: 14 119 727,94 PLN
Dofinansowanie z Unii Europejskiej: 10 799 507,65 PLN
Efekty
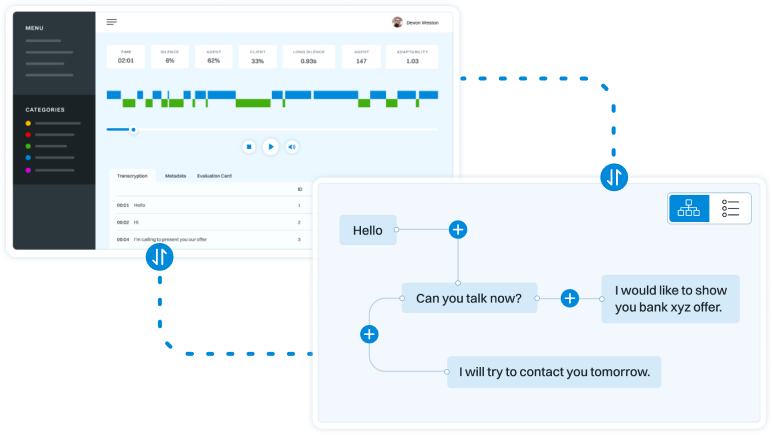
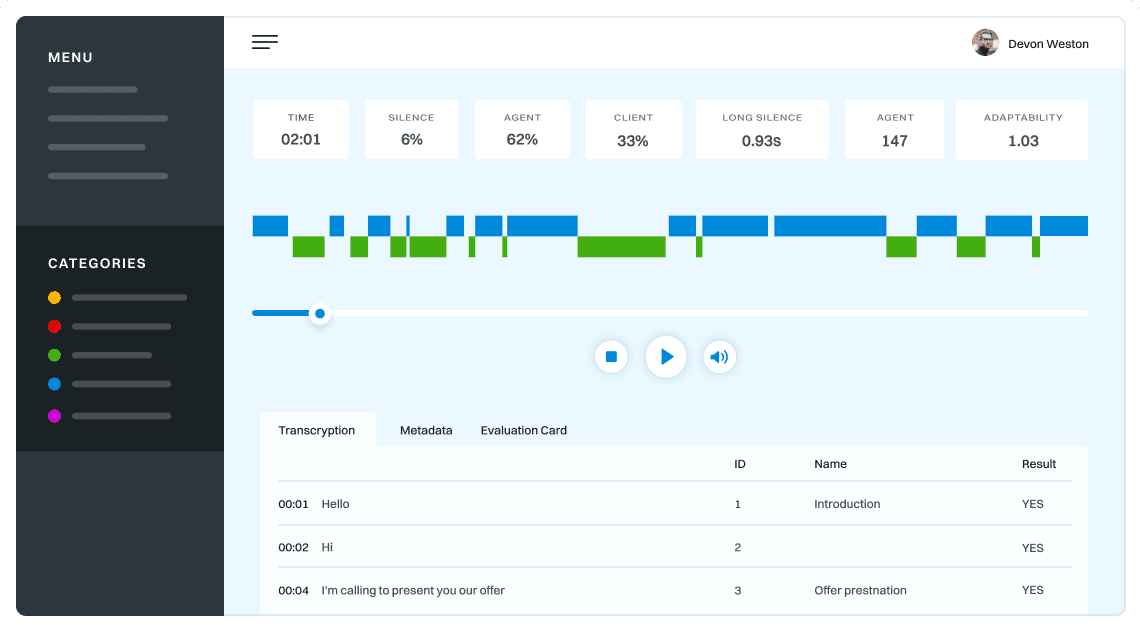
Rezultatem realizacji projektu będzie prototyp platformy do tworzenia nowej generacji systemów dialogowych (Conversational Intelligence) w oparciu o importowane przykłady ludzkich zachowań komunikacyjnych, tj. dialogi w kanale głosowym i tekstowym, wypowiedzi, rozmowy, reakcje etc. System będzie miał charakter wielojęzyczny i multimodalny. Platforma będzie pozwalała na naturalne projektowanie modeli konwersacyjnych w oparciu o zaimportowane przykłady takich zachowań (domenowe dialogi, wypowiedzi, rozmowy, reakcje etc.), które zostaną przeanalizowane z wykorzystaniem: automatycznej transkrypcji mowy, automatycznej kategoryzacji, definiowania i identyfikacji pragmatycznych znaczników dyskursu, symulowania zachowań oraz inferencji gramatyki. Po wstępnym rozpoznaniu i kategoryzacji, zdiaryzowane próbki wypowiedzi podzielone zostaną na zestaw kroków (intencji i akcji) i zamodelowane do postaci grafowej. Na podstawie tak zanalizowanych i przedstawionych danych system będzie automatycznie generował modele zachowań komunikacyjnych odwzorowujące zachowania komunikacyjne analogiczne do tych, które występowały w zaimportowanych przykładach. Modele te będą mogły podlegać ręcznej modyfikacji w celu ich lepszego dopasowania z wykorzystaniem graficznego interfejsu. Platforma zostanie wyposażona w bogate narzędzia umożliwiające testowanie i weryfikację działania systemu poprzez budowę predefiniowanych modeli i słowników, które będą stanowiły bazę testową dla pojedynczych elementów systemu, jak i dla wszechstronnego testowania całego procesu.

Trójmiejska firma VoiceLab uzyskała dofinansowanie na rzecz rozwijania swojej działalności. Projekt jest realizowany w ramach Regionalnego Programu Operacyjnego Województwa Pomorskiego na lata 2014–2020.
Tytuł projektu
Opracowanie systemu Automatycznego Rozpoznawania Mowy (ARM) VoiceLab w oparciu o głębokie sieci neuronowe DNN (Deep Neural Networks) i stworzenie innowacyjnego systemu zbierania danych i treningu modeli akustycznych RAMD (Rapid Acoustic Model Development) w celu osiągnięcia superhuman performance.
Streszczenie projektu
Projekt polega na zbudowaniu systemu ARM (Automatyczne Rozpoznawanie Mowy) VoiceLab osiągającego skuteczność rozpoznawania mowy dorównującą człowiekowi w analogicznych warunkach akustycznych (super human performance) w oparciu o głębokie sieci neuronowe DNN (Deep Neural Network). Dzięki wykorzystaniu bardzo dużych ilości danych treningowych nowy system ARM VoiceLab będzie w stanie rozpoznawać mowę w trudnych warunkach akustycznych na poziomie porównywalnym do najlepszych tego typu rozwiązań na świecie. System ARM VoiceLab będzie również niezależny względem typu języka.
Okres realizacji
Od: 2016-07-01.
Do: 2020-06-30.
Wydatki projektu
Wartość ogółem: 7 019 161,85 PLN.
Koszty kwalifikowalne: 6 756 041,85 PLN.
Wnioskowane dofinansowanie UE: 4 678 455,03 PLN.
Wkład własny: 2 340 706,82 PLN.
Efekty
skuteczności poprzez dobór architektury modelu akustycznego skalującego się dla dużych ilości nagrań mowy. Lepsza skuteczność polega na opracowaniu optymalnych parametrów pod kątem wydajności i szybkości działania systemu rozpoznawania mowy poprzez badanie i porównanie różnych struktur budowy dekodera opartego o HMM/GMM, HMM/DNN, DNN na dużych i małych zbiorach danych. Dodatkowym celem jest wprowadzenie algorytmów wpływających na poprawę jakości rozpoznawania przez system ARM w warunkach zaszumionych oraz zbadanie wpływu języka na skuteczność rozpoznawania mowy. Równorzędnym celem projektu jest również zbudowanie systemu do szybkiego zbierania danych wykorzystywanych do treningu modeli akustycznych RAMD (Rapid Acoustic Model Development). System ten będzie umożliwiał iteracyjnie prowadzenie badań i kontynuowanie dalszych prac rozwojowych nad rozpoznawaniem mowy.
Publikacje