

Natural Language Processing
Generating paraphrases
Generating paraphrases

TRURL brings additional support for specialized analytical tasks:
Dialog structure aggregation
Customer support quality control
Sales intelligence and assistance
TRURL can also be implemented effectively on-premise:
We will build a GPT model for you
Trained securely on your infrastructure
Trained on your dataset

Share

Text summarization is the task of creating a new, shorter version of input text by reducing the number of words and sentences without changing their meaning and keeping their key parts.
There are many techniques for pulling out the most important data from input text but most of them fall into one of two approaches: Extractive or Abstractive. In this article, you will get the chance to get to know more about abstractive text summarization.
Transfer learning, where a model is first pre-trained on a data-rich task before being finetuned on a downstream task, has emerged as a powerful technique in natural language processing (NLP). The effectiveness of transfer learning has given rise to a diversity of approaches, methodologies, and practices. If you are just starting with the task of text summarization you should know about BART and T5.
Before jumping into mentioned models let’s talk about BERT. This model was introduced in 2018 by Google. It is pre-trained to try to predict masked tokens and uses the whole sequence to get enough info to make a good guess. This works well for tasks where the prediction at position i is allowed to utilize information from positions after i, but less useful for tasks, like text generation, where the prediction for position i can only depend on previously generated words.
BART and T5 differ from Bert by:

add a causal decoder to BERT’s bidirectional encoder architecture,
replace BERT’s fill-in-the-blank cloze task with a more complicated mix of pretraining tasks.
Now let’s dig deeper into the big Seq2Seq pretraining idea!
Documentation: https://huggingface.co/docs/transformers/model_doc/bart
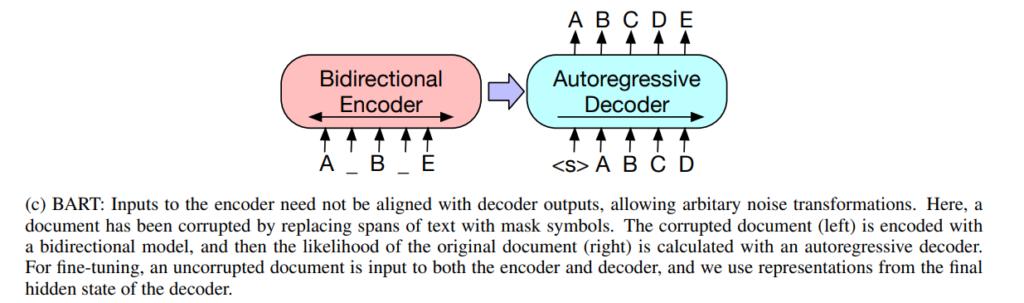
Figure from the BART paper
BART(facebook) is a well-known model used in many implementations of text summarization tasks. It is a denoising autoencoder using a standard seq2seq/machine translation architecture with a bidirectional encoder (like BERT) and a left-to-right decoder (like GPT).
Sequence-to-sequence format means that BART inputs and outputs data in sequences. In the task of creating summaries, the input consists of raw text data and pre-trained model outputs created summarization.
Documentation: https://huggingface.co/docs/transformers/model_doc/t5
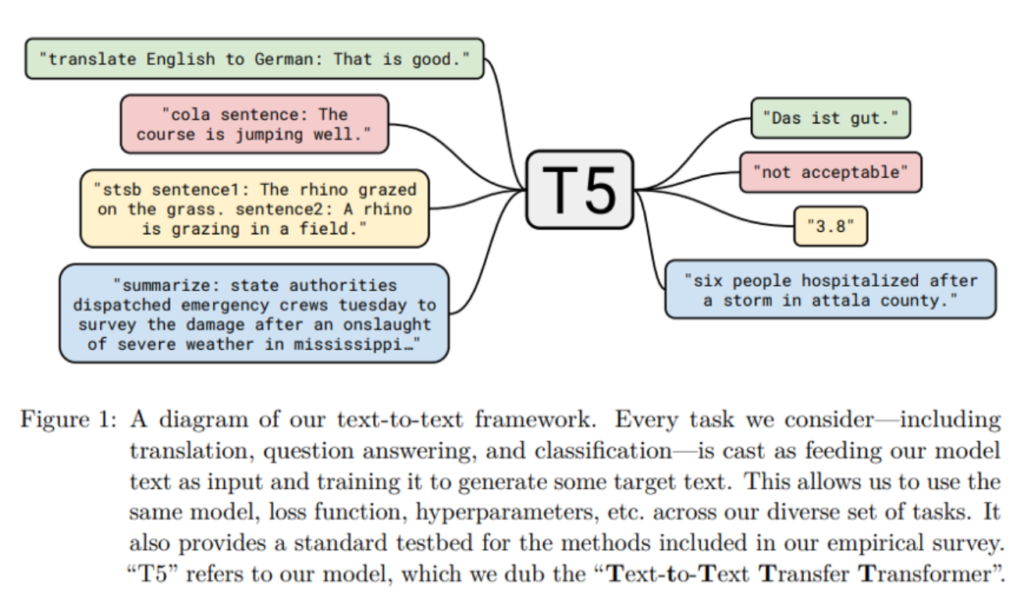
T5 Model Task Formulation.
T5 is a Text-to-Text transfer transformer model from Google. It is trained in an end-to-end manner with text as input and modified text as output. This format makes it suitable for many NLP tasks like Summarization, Question-Answering, Machine Translation, and Classification problems. Google made it very accessible to test pre-trained T5 models for summarization tasks, all you need to do is follow this tutorial to see how it works.
Google has released the pre-trained T5 text-to-text framework models which are trained on the unlabelled large text corpus called C4 (Colossal Clean Crawled Corpus) using deep learning. C4 is the web extract text of 800Gb cleaned data.
Google has released the pre-trained T5 text-to-text framework models which are trained on the unlabelled large text corpus called C4 (Colossal Clean Crawled Corpus) using deep learning. C4 is the web extract text of 800Gb cleaned data.
T5-small with 60 million parameters.
T5-base with 220 million parameters.
T5-large with 770 million parameters.
T5-3B with 3 billion parameters.
T5-11B with 11 billion parameters.
T5 expects a prefix before the input text to understand the task given by the user. For example, “summarize:” for the summarization. If you want to learn how to finetune a t5 transformer jump into this article.
Besides learning about popular models like BART or T5 you will want to keep up with the newest models achieving SOTA. Papers with code has a whole page on abstractive text summarization. Leaderboards in the Benchmark section are used to track progress for this task.
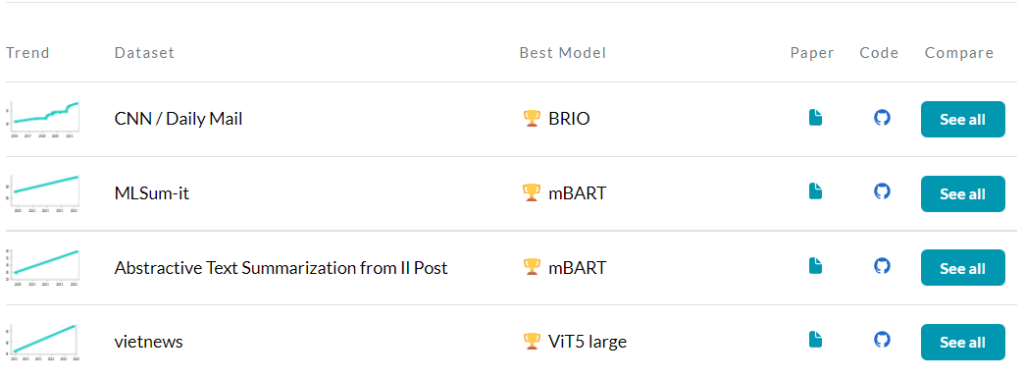
You can choose a Dataset and see results for some models and different metrics.
pros:
It is easy to implement. You can quickly get started with finetuning existing pre-trained models with your data and get generated summaries.
Unlike for extractive text summarization approach, you don’t need to implement additional techniques for extracting specified data.
cons:
models tend to generate false information. It happens at either the entity level (extra entities are generated) or entity relation level (context in which entities occur is incorrectly generated). In the paper Entity-level Factual Consistency of Abstractive Text Summarization authors proposed a new metric for measuring the factual consistency of entity generation. If you are interested in this article here is an approachable summarization.
the quality of generated summaries depends on how good is your model. The best models can sometimes take up a lot of memory during training, creating a need for better GPUs.
You might have already heard some version of the quote “A machine learning model is only as good as the data it is fed”, Let’s explore this topic remembering how important it is for achieving a successful outcome.
At this point, we know a bit about existing models and where to find their documentation. You might have already tested some of them and now want to try finetuning one, but you don’t have your rich dataset? A good place to look for them is on papers with code. There are 41 datasets in total for this task.
If you want to take a look at some of the most popular ones jump into Part 1: Extractive summarization in a nutshell
As mentioned before measuring the quality of generated summaries can be complicated. The most common set of metrics used for measuring the performance of a summarization model is called the ROUGE score.
ROUGE score computes how much of the generated text overlaps with a human-annotated summary. The higher the score the higher overlap. It considers consecutive tokens called n-grams. In practice most commonly used versions are:
ROUGE 1 – measures 1-grams (single words)
ROUGE 2 – measures 2-grams (2 consecutive words)
ROUGE L – measures longest matching sequence of words using LCS.
This metric works well for getting a sense of the overlap but not for measuring factual accuracy. There are 2 unwanted scenarios:
a factually incorrect summary that consists of the same words as the reference summary. Although a different sequence of words results in a wrong meaning the ROUGE score returns a high value.
Reference summary: The dog sat on the blue mat.
Machine generated: The mat sat on the blue dog.
rouge1: 1.0 rougeL: 0.714
a factually correct summary that consists of different words that a human would consider as correct. The overlap will be poor resulting in a low ROUGE score.
Reference summary: She lived in a red home.
Machine generated: She used to have a burgundy house.
rouge1: 0.285 rougeL: 0.285
Because metrics such as ROUGE have serious limitations many papers carry out additional manual comparisons of alternative summaries. Such experiments are difficult to compare across papers. Therefore, claiming SOTA based only on these metrics can be problematic.
In response to this issue there have been implemented new approaches:
previously mentioned method for calculating factual consistency of entities generation Entity-level Factual Consistency of Abstractive Text Summarization
InfoLM is a family of untrained metrics that can be viewed as a string-based metric but it can robustly handle synonyms and paraphrases using various measures of information (e.g f-divergences, Fisher Rao). It can be seen as an extension of PRISM. The best performing metric is obtained with AB Divergence. The Fisher-Rao distance, denoted by R, achieves good performance in many scenarios and has the advantage to be parameter-free.
This article covered all the main aspects of abstractive text summarization and a few popular challenges associated with it.
BART Docs:
https://huggingface.co/docs/transformers/model_doc/bart
BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension :
https://arxiv.org/pdf/1910.13461v1.pdf
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer:
https://arxiv.org/pdf/1910.10683.pdf
T5 Docs:
https://huggingface.co/docs/transformers/model_doc/t5
T5 models:
https://huggingface.co/models?search=T5
Tutorial for finetuning T5:
https://towardsdatascience.com/fine-tuning-a-t5-transformer-for-any-summarization-task-82334c64c81
Papers With Code | Abstractive text summarization:
https://paperswithcode.com/task/abstractive-text-summarization#datasets
To ROUGE or not to ROUGE?:
https://towardsdatascience.com/to-rouge-or-not-to-rouge-6a5f3552ea45
Entity-level Factual Consistency of Abstractive Text Summarization:
https://arxiv.org/pdf/2102.09130.pdf
Summarization of the above article:
InfoLM:
https://www.aaai.org/AAAI22Papers/AAAI-4389.ColomboP.pdf
Share
Author: Alicja Golisowicz

