

Natural Language Processing
Generating paraphrases
Generating paraphrases

TRURL brings additional support for specialized analytical tasks:
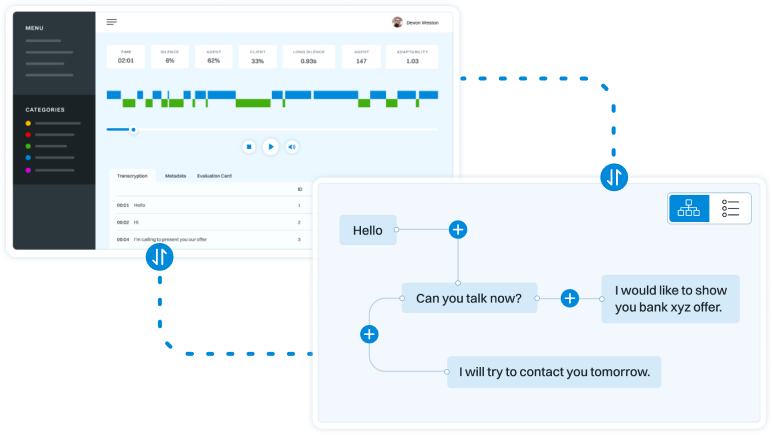
Dialog structure aggregation
Customer support quality control
Sales intelligence and assistance
TRURL can also be implemented effectively on-premise:
We will build a GPT model for you
Trained securely on your infrastructure
Trained on your dataset

Share

According to Wikipedia text summarization “is the process of shortening a set of data computationally, to create a subset (a summary) that represents the most important or relevant information within the original content”. So, in short, it’s about extracting only essential information.
There are two main approaches: abstractive and extractive. Transfer learning with the use of transformers is a way to go in both.
In abstractive text summarization are used models such as T5 or BERT. After a proper training model is able to generate summaries based on given text.
On the other hand we have an extractive approach: localize the most important parts of the text and then combine them into a summary. In the end parts of the resulting summary come from the original text meanwhile in an abstractive solution model summarizes text with new phrases but keeping the point the same.
To begin with, the main advantage is that sometimes (especially when we don’t have a good or big dataset) extractive summarization is a better option to choose because an abstractive approach can generate some fake information.
In terms of disadvantages: summaries can be stiff and repetitive, devoid of language grace. Also the overall quality highly depends on your data and model quality.
First and the most difficult thing is to find the best suited to your needs dataset. Some sample datasets are available on Papers with code.
Let’s begin.

CNN/Daily Mail: human generated abstractive summary bullets were generated from news stories in CNN and Daily Mail websites as questions (with one of the entities hidden), and stories as the corresponding passages from which the system is expected to answer the fill-in the-blank question. The corpus has 286,817 training pairs, 13,368 validation pairs and 11,487 test pairs.
DebateSum: DebateSum consists of 187328 debate documents, arguments (also can be thought of as abstractive summaries, or queries), word-level extractive summaries, citations, and associated metadata organized by topic-year. This data is ready for analysis by NLP systems.
WikiHow: WikiHow is a dataset of more than 230,000 article and summary pairs extracted and constructed from an online knowledge base written by different human authors. The articles span a wide range of topics and represent high diversity styles.
SAMSum Corpus: a new dataset with abstractive dialogue summaries.
Besides data we need a machine learning model to feed it. Training a transformer from zero is highly time & resource consuming. Fortunately, we have access to many models that require only fine-tuning to tailor your needs.
But what exactly is a transformer? If this question just popped out in your mind, please learn more in this post.
So, in terms of extractive text summarization the most popular one is a BERT: a transformer developed by Google, created and published in 2018. It’s a bidirectional transformer pretrained using a combination of masked language modeling objective & next sentence prediction on a large corpus comprising for example Wikipedia.
The original English-language BERT has two models:
the BERT BASE: 12 encoders with 12 bidirectional self-attention heads,
the BERT LARGE: 24 encoders with 16 bidirectional self-attention heads.

Bert
Another powerful model is a T5 created in 2020 also by Google. It’s an encoder-decoder model pre-trained on a multi-task mixture of unsupervised and supervised tasks and for which each task is converted into a text-to-text format. Interestingly, T5 works by prepending a different prefix to the input corresponding to each task, e.g., for translation: translate English to German: …, for summarization: summarize: …..
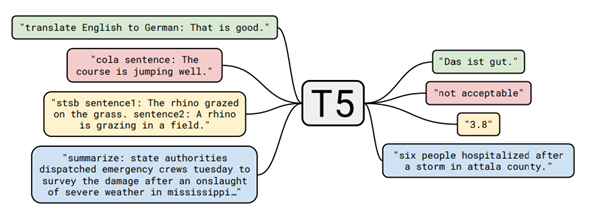
T5 tasks visualisation
If you wanna learn more check out papers with code.
Now when we have both the dataset and the model let’s begin training. But how do I know if my summaries are accurate or not?
The metrics compare our model-generated summary against reference (high-quality and human-produced) summaries. The most popular set of metrics to evaluate the quality of generated summary is the ROGUE. Let’s take a closer look.
Reference: The kitten is tiny and cute.
Summary: Small kitten is cute.

Kittens
ROUGE-N measures the number of matching n-grams between the generated text and a reference. For the ROUGE-1 precision will be computed as the ratio of the number of tokens in summary that are also in our reference: “kitten”, “is” and “cute”. Length of summary is 4, so the overall precision is 3/4.
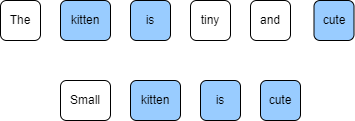
ROUGE-1 recall is inverted: it’s simply the ratio of the number of unigrams in reference that appear also in summary over the length of reference, so in our case: 3/6.
The ROUGE-2 can be calculated by analogy.
In fact the most used are:
ROGUE-1
ROGUE-2
ROUGE-L (based on the longest common subsequence: LCS)
Unfortunately ROUGE score does not manage different words that have the same meaning, as it measures syntactical matches rather than semantics.
In the approach presented in the paper “Fine-tune BERT for Extractive Summarization”, when predicting summaries for a new document, we first use the models to obtain the score for each sentence. We then rank these sentences by the scores from higher to lower, and select the top-3 sentences as the summary.
For the example we’ll only select the top-1 sentence.
Sample text (from CNN/Daily Mail dataset):
[1] Never mind cats having nine lives. [2] A stray pooch in Washington State has used up at least three of her own after being hit by a car, apparently whacked on the head with a hammer in a misguided mercy killing and then buried in a field – only to survive.
[3] That’s according to Washington State University, where the dog – a friendly white-and-black bully breed mix now named Theia – has been receiving care at the Veterinary Teaching Hospital.
[4] Four days after her apparent death, the dog managed to stagger to a nearby farm, dirt-covered and emaciated, where she was found by a worker who took her to a vet for help.
So, the above data has 4 sentences. If we feed the model, the output can be:
[0.1; 0.5; 0.2; 0.2]
As we see, the second sentence scores the highest & it’ll be included in the summary.
This example has been simplified for ease of understanding by inexperienced persons. In the paper authors build several summarization-specific layers stacked on top of the BERT outputs, to capture document-level features for extracting summaries. These summarization layers are jointly fine-tuned with BERT. For the curious code is available here.
This article was an introduction to the task of extractive summarization. I hope it was a fun adventure 🙂 If you want to learn more, see Part 2: Abstractive text summarization.
https://en.wikipedia.org/wiki/Automatic_summarization
https://en.wikipedia.org/wiki/BERT_(language_model)
https://medium.com/nlplanet/two-minutes-nlp-learn-the-rouge-metric-by-examples-f179cc285499
Bert: https://muppety.fandom.com/pl/wiki/Bert
Kittens: https://www.publicdomainpictures.net/en/view-image.php?image=167326&picture=cat-on-the-white
Author: Patrycja Biryło

