

Natural Language Processing
Generating paraphrases
Generating paraphrases

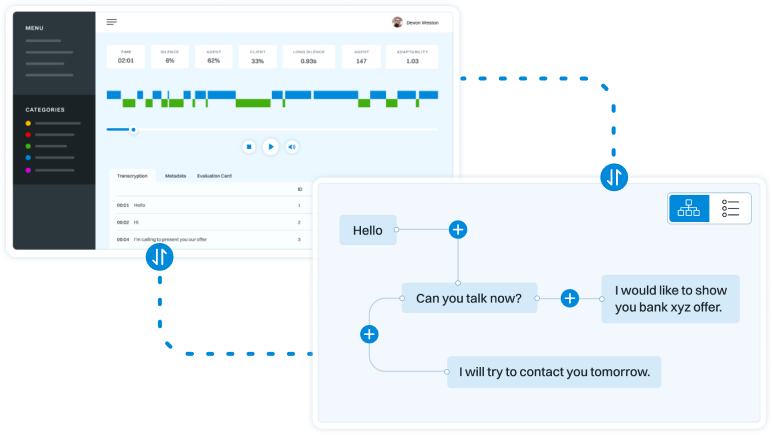
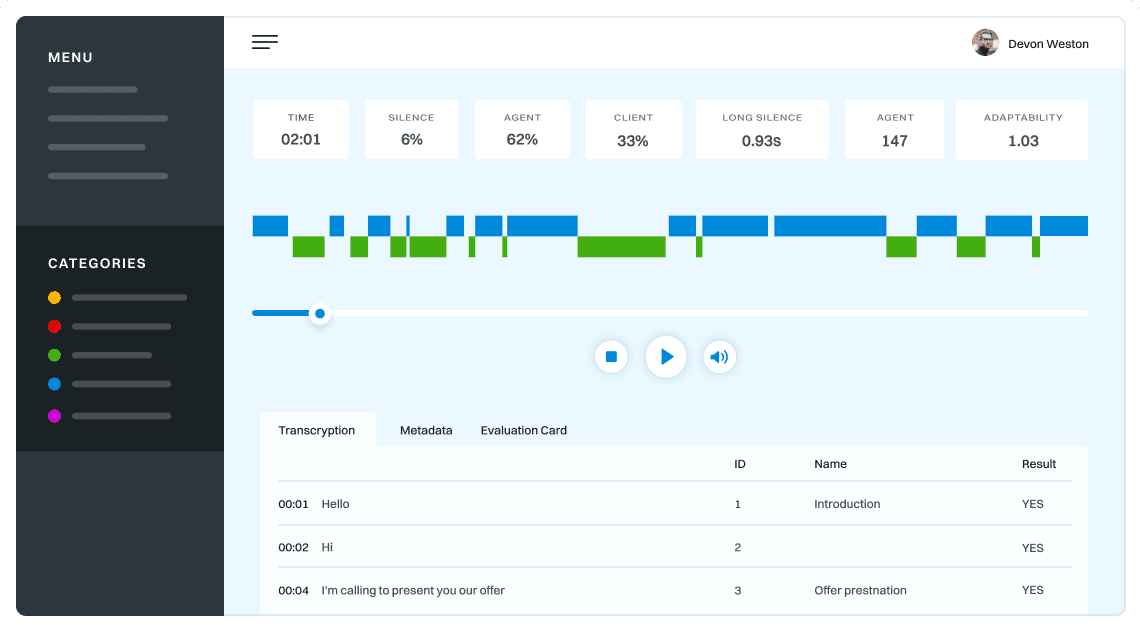
TRURL brings additional support for specialized analytical tasks:
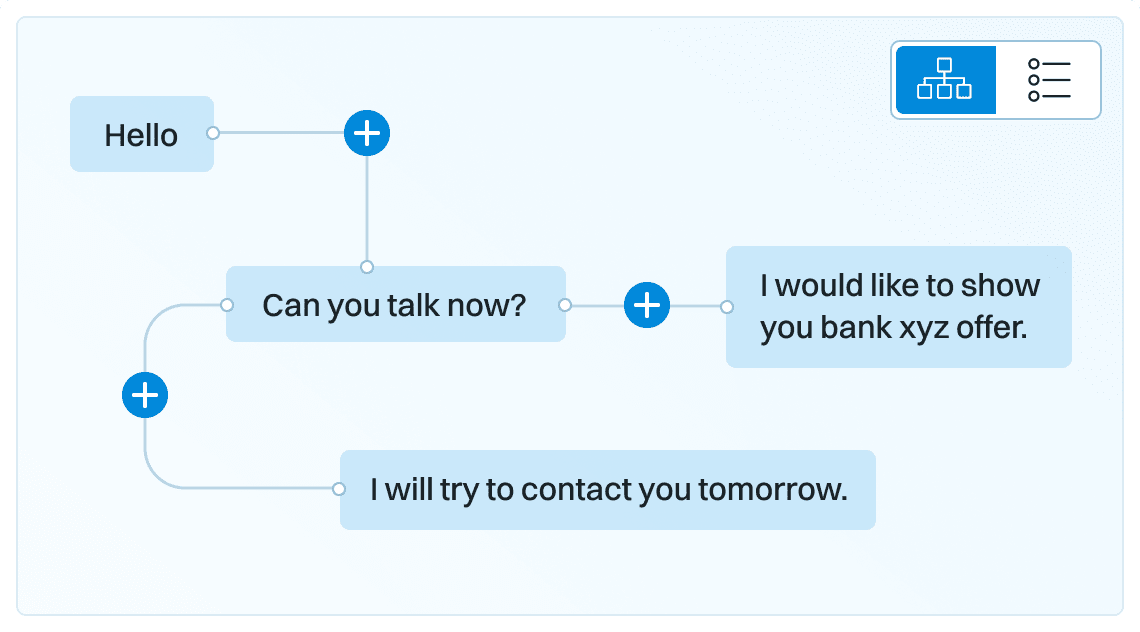
Dialog structure aggregation
Customer support quality control
Sales intelligence and assistance
TRURL can also be implemented effectively on-premise:
We will build a GPT model for you
Trained securely on your infrastructure
Trained on your dataset

Share
What do you think, when you hear ‘Transformer’? Is it a robot? A component used in an electrical circuit? Or maybe a neural network? If you want to find out something about the last one, welcome to read it!
Transformers are the family of neural networks mainly used in Natural Language Processing (NLP) and were introduced relatively recently – in 2017 by Vaswani et al., in the paper “Attention Is All You Need” (link). A fancy title indeed communicates the main idea of the architecture.
Previously, in NLP there were mostly used recurrent neural networks (RNN). Although having satisfying results, they had a drawback of computation time, as they consider a long sequence of words at a time. Here, as a rescue come transformers because they don’t operate on the whole sequence but only on the attention relationships between embeddings (numerical representation of words).
Previous architectures were based on the encoder-decoder structure. The encoder had to create a vector representing the input sentence and then passed as an input to the decoder.
Attention mechanism assumes passing all the encoder states to the decoder so that the model can choose which information it considers as most important.
In figure 1 you can see the idea of the attention mechanism in the translation process. Although the idea might seem simple, it was a breakthrough in the field of natural language processing.
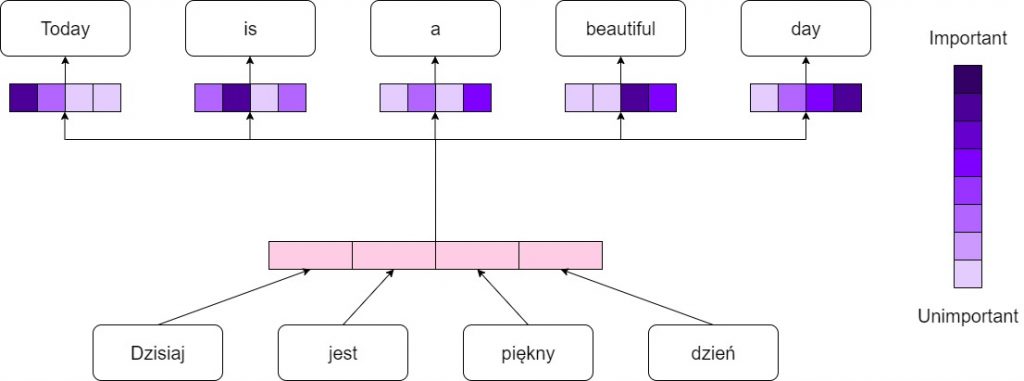
Attention mechanism
When we consider a self-attention mechanism the difference is that the choice of which part of the input is the most important is made during the encoding process – inputs interact with each other scoring with the “attention points”.
As you can see in figure 2, the encoder consists of n layers with two sub-layers inside each of them. One is a Multi-Head Attention that independently learns the self-attention between words and the second one is a fully connected feed-forward network. The sublayers are joined together by the residual connections followed by the normalization block.
The Transformer architecture
The decoder has a pretty similar structure, however, each layer has additionally a third sub-layer, which is a Multi-Head Attention over the output of the encoder.
The Multi-Head Attention mechanism is performed on three vectors – Query, Key and Value. The query may be considered as a current word (embedding), while value is the information it carries. A key is just a form of order of values, like indexing.
Transformers allow for text analysis from a different perspective – not as a sequence of words, but rather the gist of the message. It’s a huge advantage as normally the order of words in the sentence differs depending on the language, speaker, etc. Although Transformers are more efficient in terms of computation, they need a huge amount of data to be trained which is a common problem regarding machine-learning issues.
Fortunately, there are models that might be used as a base for transfer learning like e.g. HerBERT (link). This model was introduced in 2021 by polish scientists from Allegro.pl. It is based on the BERT – the most known model for NLP created by Google and adjusted to the difficult polish language. In the KLEJ classification, it managed to reach 88,4 out of 100 points which is the state of the art result regarding polish models.
To use the model you can simply put it like this:
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("allegro/herbert-base-cased")
model = AutoModel.from_pretrained("allegro/herbert-base-cased")
output = model(
**tokenizer.batch_encode_plus(
[
(
"Język – ukształtowany społecznie system budowania wypowiedzi, używany w procesie komunikacji.",
"Język służy do przedstawiania rzeczywistości dotyczącej przedmiotów, czynności czy abstrakcyjnych pojęć za pomocą znaków.",
)
],
padding='longest',
add_special_tokens=True,
return_tensors='pt'
)
)
In this case, you have to define a tokenizer – a tool to divide input into separate tokens – words and a model that you want to use – i.e. herbert-base-cased. As an input to the model, you put a tokenized text.
Depending on what you want to do, you can use HerBERT with an appropriate Head Model for different purposes, i.e.:

Predicting a masked word in the sentence,
Predicting the next word,
Predicting the next sentence,
Answering questions
As an output, you get a desired word or sequence of words.
Computer Vision is one of the fields where machine learning is gaining the most interest. Most of the solutions apply to vision problems. Even analysis of a signal is sometimes transformed to an ‘image form’ and then processed by a network. If so, why not give it a try for a reverse operation?
The usage of Transformer in image recognition was introduced in the paper “An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale” (link) in 2020 by Dosovitskiy et al.
The main idea was to divide an image into smaller patches of the same shape. Let’s imagine, that each of these patches is a ‘word’. Next, we have to vectorize them. This means, putting all the values from one patch into a vector with a given order. From each vector x then are created functions z with parameters W and b which are the parameters of the network learned in the training process. Additionally, there is added information about positional encoding. It is important to keep the correct order of the patches. Then the Multi-Head Self-Attention layer comes and the magic happens, as in the original Transformer.
As you can see in figure 3, the whole model does not vary much. It’s the input preparation that has to be different than in the original transformer.
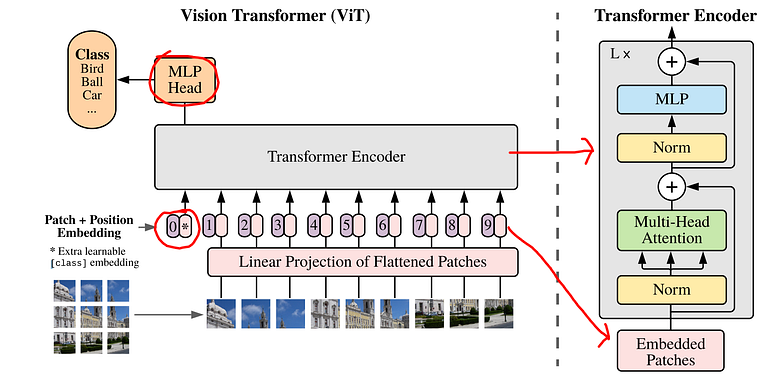
Vision Transformer architecture
To use the Vision Transformer model you can use a timm library:
import timm
import PIL
import torchvision.transforms as T
model_name = "vit_base_patch16_224"
model = timm.create_model(model_name, pretrained=True)
IMG_SIZE = (224, 224)
NORMALIZE_MEAN = (0.5, 0.5, 0.5)
NORMALIZE_STD = (0.5, 0.5, 0.5)
transforms = [
T.Resize(IMG_SIZE),
T.ToTensor(),
T.Normalize(NORMALIZE_MEAN, NORMALIZE_STD),
]
img = PIL.Image.open('samochod.jpg')
img_tensor = transforms(img).unsqueeze(0)
output = model(img_tensor)
You can define a model from the library. It’s an already pre-trained model, ready to use. As an input, you provide an image as a tensor – a common type of data used in computer vision. As an output, you get a class to which the object belongs and a score of confidence. It’s important that you don’t have to do all the input preprocessing manually, this is done for you 😊
Both Transformer and Vision Transformer are based on the same idea – attention. As long as the model engine is the same in both of them, a distinct difference is visible in the input and output. A standard form of providing text into the model is tokenization. The image has to be transferred to a similar form – cut into small pieces and put in order. The output also differs as the aim of the task is different. When providing text, we want to “explore the unknown” – see something that we do not know yet, while during the image processing we rather want to analyze what is visible in it.
Most of the commonly used models in NLP are based on the Transformer. Mostly, they are used in bots as a form of communication with the customer.
When it comes to Vision Transformers, they gain popularity among other great models. They can be used in image classification, detection or segmentation, for example in medical image analysis.
As every model, Transformers have their pros and cons. Training a valuable transformer from scratch is extremely hard – huge amounts of data and computational power are needed. However, usage of already existing ones gives an opportunity to benefit from their ability to “read the context”. Considering various problems – context is rather more important than details.
To sum up – Attention is all you need! 😊
Share
Author: Maria Ferlin, Politechnika Gdańska
Resources:

