
Text-To-Speech
Speech and Audio Processing
Speech and Audio Processing

TRURL brings additional support for specialized analytical tasks:
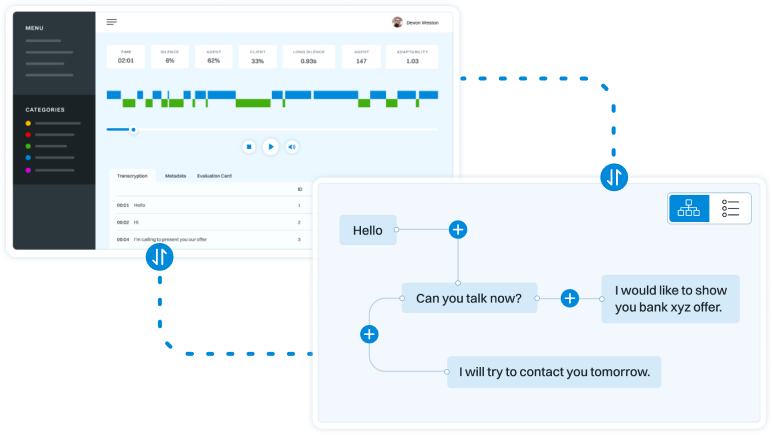
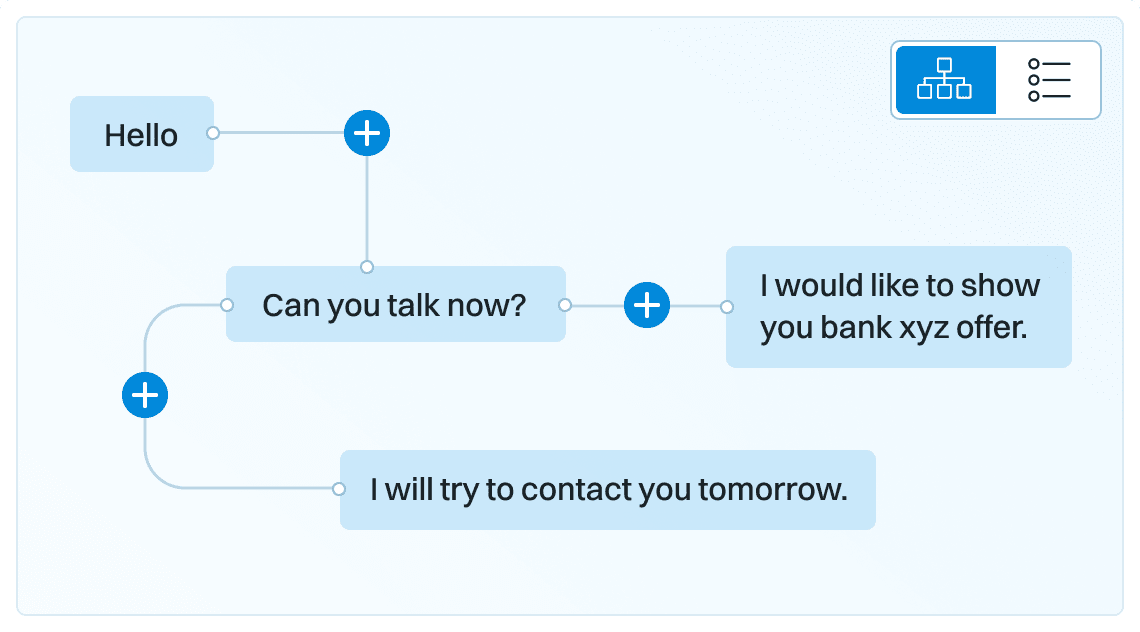
Dialog structure aggregation
Customer support quality control
Sales intelligence and assistance
TRURL can also be implemented effectively on-premise:
We will build a GPT model for you
Trained securely on your infrastructure
Trained on your dataset

Share

We use paraphrases every day, but who among us has ever thought about using them? Paraphrases are used, among others, in search engines: they help the customer find the product more easily, suggest other ways to search. Thanks to them, we can also expand data sets and many more.
Let’s see our model for paraphrasing.
The rest of the article is available on the link below: https://colab.research.google.com/drive/1RdfRxJzhEcmjg_4iNMKz_lok0AamufgK?usp=sharing#scrollTo=a14fba00
(NOTICE) In order to be able to use the notebook and send requests to our services, you have to upload a 'credentials.ini’ file to the runtime workspace (the main directory, next to sample_data folder). You can obtain one by getting in touch over at https://voicelab.ai/contact.
Author: Ptrycja Biryło
Share

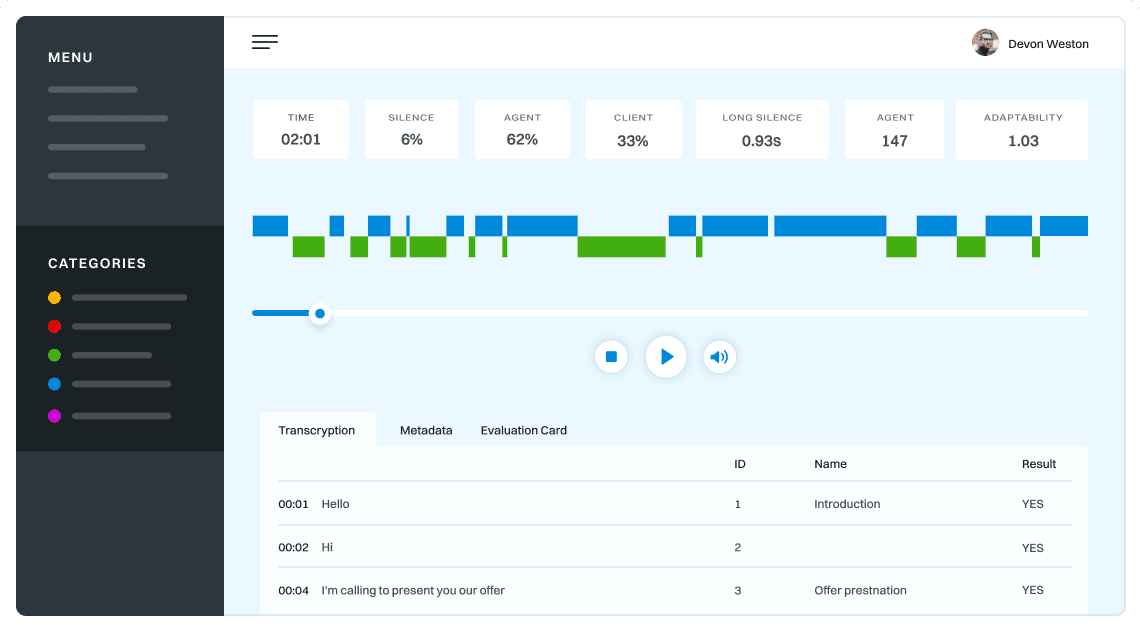
Speech processing is an application of DSP (Digital Signal Processing) to the analysis and processing of audio or speech recordings.
To produce speech the talker first formulates thought in their mind which then is transmitted to vocal cords where a message is converted into a sequence of phonemes enriched with prosody which denotes duration of sounds, the loudness of sounds and pitch associated with the sounds.
The rest of the article is available on the link below: https://hackmd.io/@4dWlJiToT2myrDj_ahTuwA/rJtxZYoOc
(NOTICE) In order to be able to use the notebook and send requests to our services, you have to upload a 'credentials.ini’ file to the runtime workspace (the main directory, next to sample_data folder). You can obtain one by getting in touch over at https://voicelab.ai/contact.
Author: Konrad Nowosadko
Share

Voice synthesis technology, also known as text-to-speech, has become increasingly popular in recent years due to its convenience and versatility. In everyday life, this technology allows individuals to access written content without having to physically read it, making it particularly helpful for those with visual impairments or reading difficulties. In business, voice synthesis systems can be leveraged to automate and streamline tasks such as customer service and call centers, allowing for faster and more efficient communication with customers.
The rest of the article is available on the link below: https://colab.research.google.com/drive/1J11-C-ndj8V6zAA41lLbbYVz3R67iG_f
(NOTICE) In order to be able to use the notebook and send requests to our services, you have to upload a 'credentials.ini’ file to the runtime workspace (the main directory, next to sample_data folder). You can obtain one by getting in touch over at https://voicelab.ai/contact.
Author: Alicja Golisowicz
Share

We are excited to announce the release of the Trurl model, a conversational AI solution designed to provide users with accurate, detailed, and polite responses to their inquiries that works similarly to ChatGPT. Trurl takes natural language processing and machine learning to the next level, offering an unparalleled degree of accuracy and relevance in its responses.
With the Trurl model, we are delivering on our commitment to providing the highest quality conversational AI solutions to our clients and partners. Whether you are a large enterprise, a small business, or an individual user, Trurl is designed to meet your needs and exceed your expectations.
We created Trurl with business purposes in mind.

Data privacy: It can be installed on-premise on the client’s server,
No limits: If you install it on-premise there are no monthly usage limits.
Well-adjusted to your needs: For bigger budgets we can securely finetune it for you on your data or for your task, For smaller companies you can “train” it yourself simply by uploading your documents and website address (no programming skills needed!),
Knows business: It was trained on speech transcripts, books, and articles, for many conversation-related tasks,
Affordable prices: Prices depend if you are using the model on-premise or on our servers. In both situations prices are affordable.
In what follows, we will provide an in-depth overview of the Trurl model, highlighting its key features and capabilities. We hope that you will find this information as exciting as we do, and that you will join us in exploring the possibilities that this innovative solution has to offer.
In this post we presented six sample use cases:
Detect arguments and objections,
Rate conversations & help make better calls,
Search through documents quickly (Information extraction),
Text summarization,
Reason for calling detection,
Creating social media posts.
Check our TRURL here for free: https://trurl.ai/
To begin with let’s see what Trurl has to say:
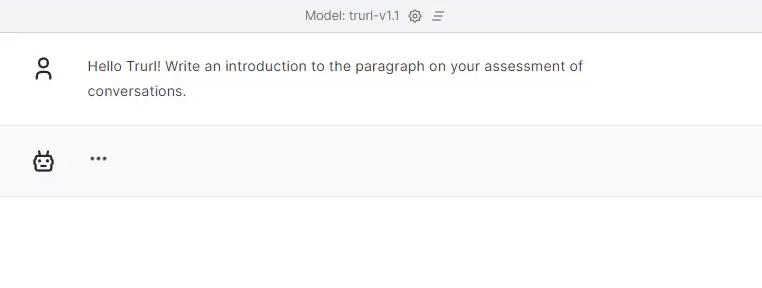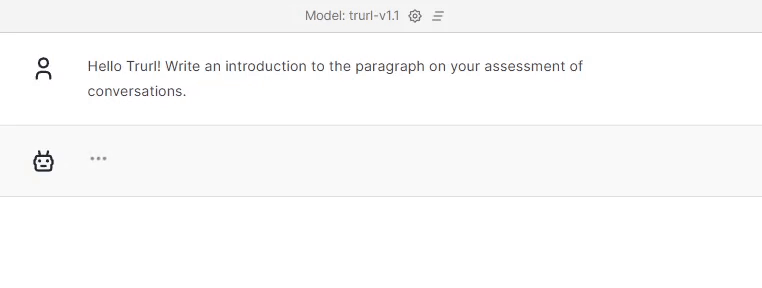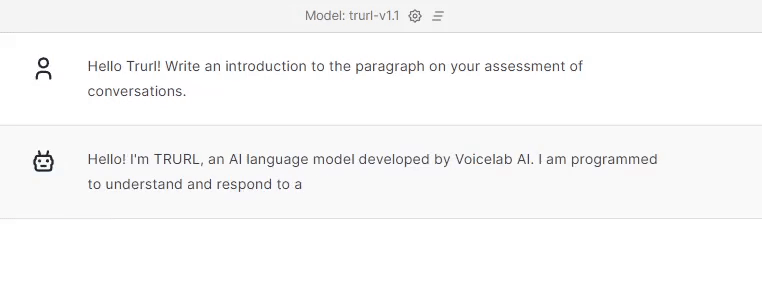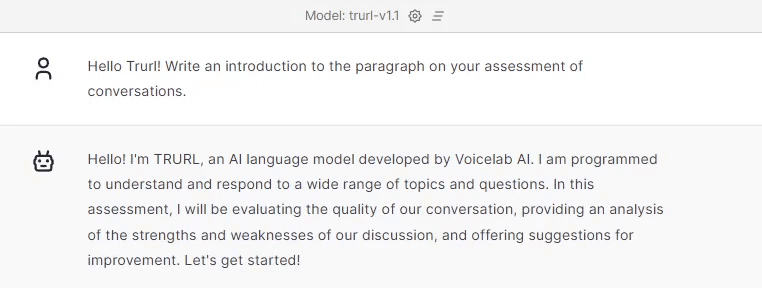
So let’s see how Trurl responds to our tasks.
Prompt:
“As a customer service quality controller, rate the following conversation. Was it an effective sales conversation? Did the client have objections during the conversation? Did the agent use arguments against the client’s objection?
conversation:
[CONVERSATION]”
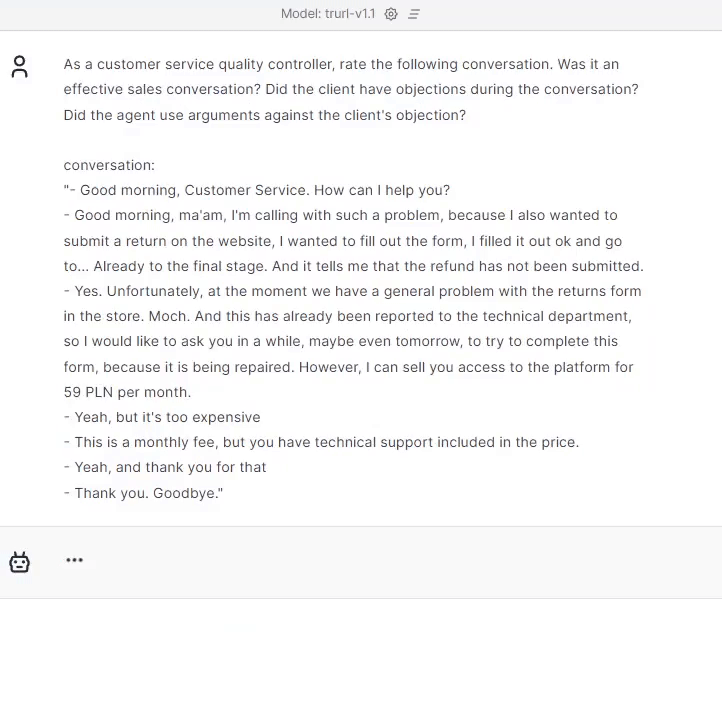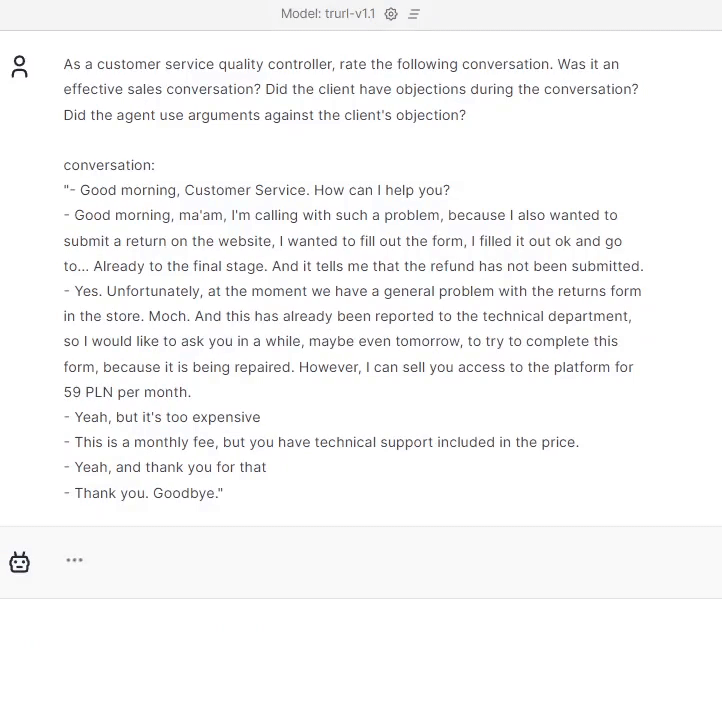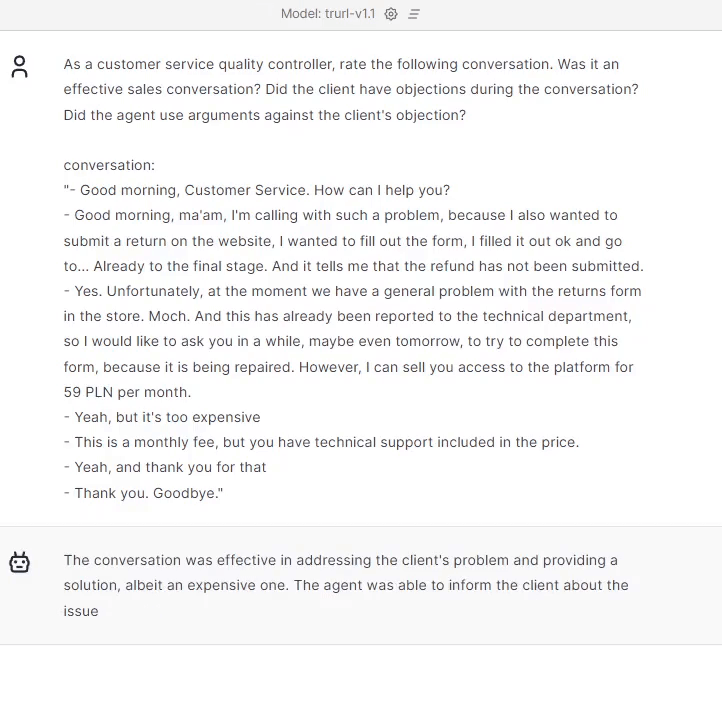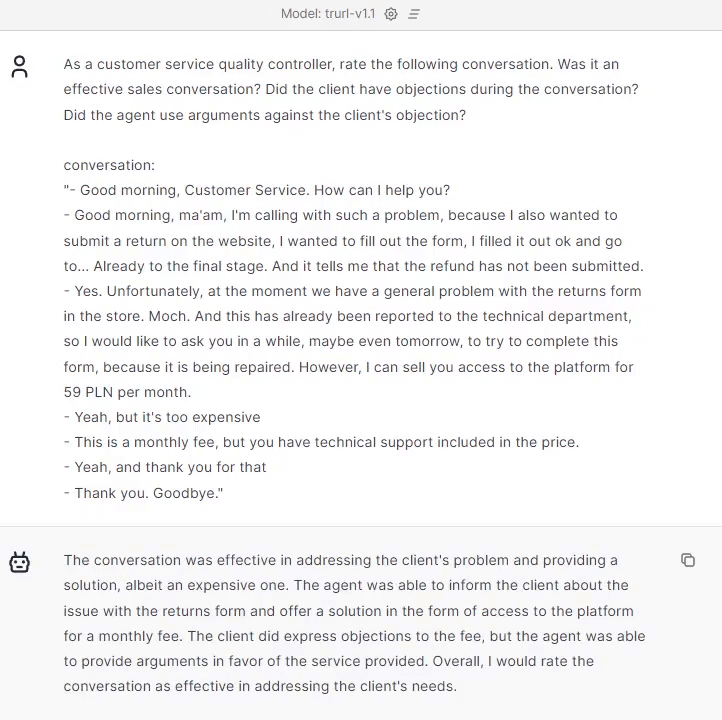
Trurl handled the assessment very well. As you can see, it covered the conversation and summed up the customer service agent’s approach in this conversation.
Maybe it can advise us?
Calls rating is an important part of any customer service operation. It allows businesses to evaluate the quality of their customer interactions and identify areas for improvement. However, calls rating can be a time-consuming and subjective process, especially when done manually. To improve the process, businesses can consider implementing a more automated system that uses AI and machine learning algorithms to analyze call data and provide more accurate ratings. Additionally, providing agents with real-time feedback and coaching can help them improve their performance and reduce the need for rating calls.
We trained Trurl to rate the conversations as well using our own call-center data with our team of experienced annotators.
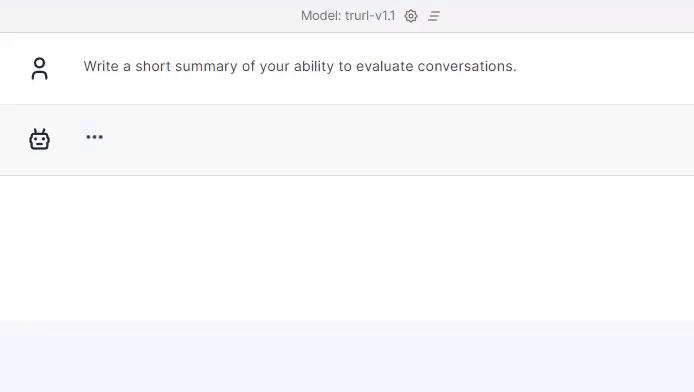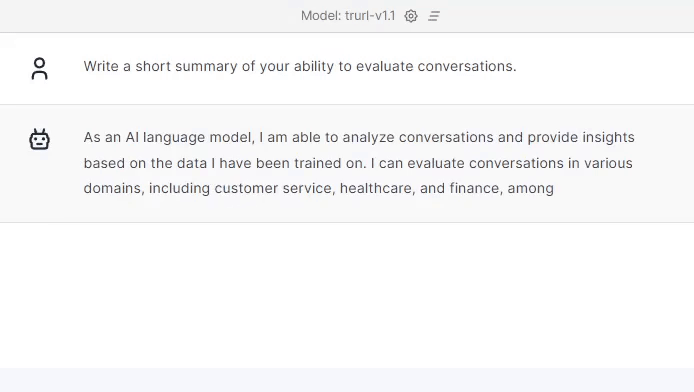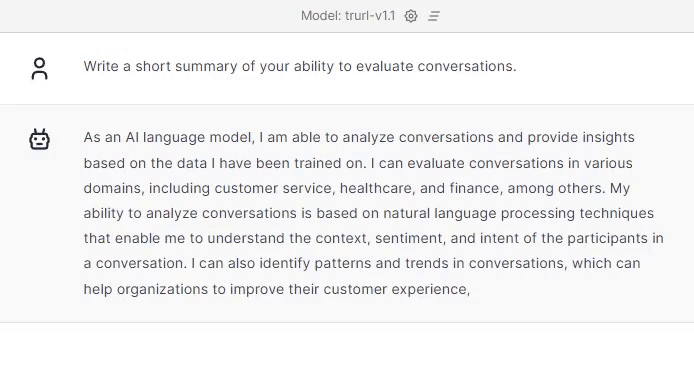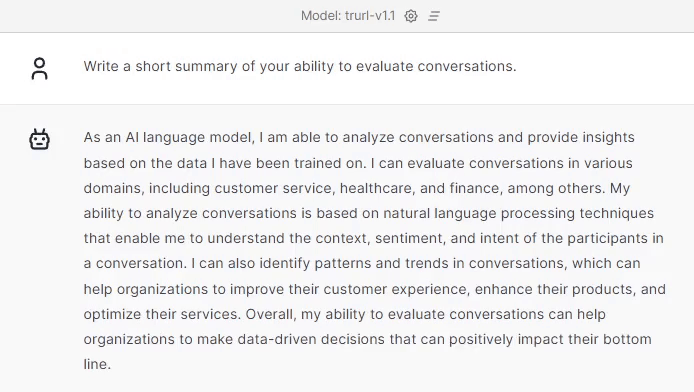
Now let’s see:
Prompt:
“Can you advise how the agent could have handled this conversation better?”
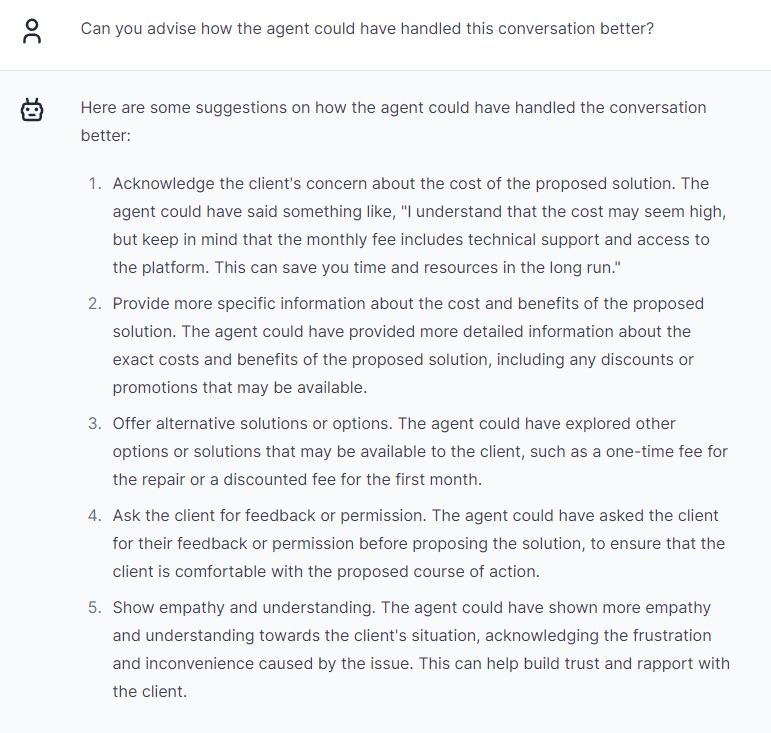
It’s great, isn’t it?
Trurl was trained to handle both quick calls and longer conversations. Here is the example of a longer and more demanding call:
Prompt:
“Rate effectiveness of conversation on a scale from 0 to 5.
[CONVERSATION]”

Overall, by using AI-powered tools to evaluate conversations, businesses can automate the process of analyzing conversations and generate objective reports on the effectiveness of each conversation. This can help to save time and resources, and can provide valuable insights into the areas where agents are performing well and where there is room for improvement.
Prompt:
“How would you rate this conversation in terms of the agent’s empathy with the client on a scale of 1 to 10? Did the agent correctly resolve the issue? What was it?
conversation:
[CONVERSATION]”

And the last example for today:
Prompt:
“As a customer service quality controller, rate the following conversation. Was it an effective sales conversation? Did the client have objections during the conversation? Was the agent kind and understanding?
conversation:
[CONVERSATION]”

Besides evaluation of conversations, Trurl can do way more. Let’s dive into other useful tasks.
Thanks to the ability to extract information, you can quickly and easily process this data and use it for other purposes, e.g. you can use our Trurl to quickly analyze files, documents or websites.
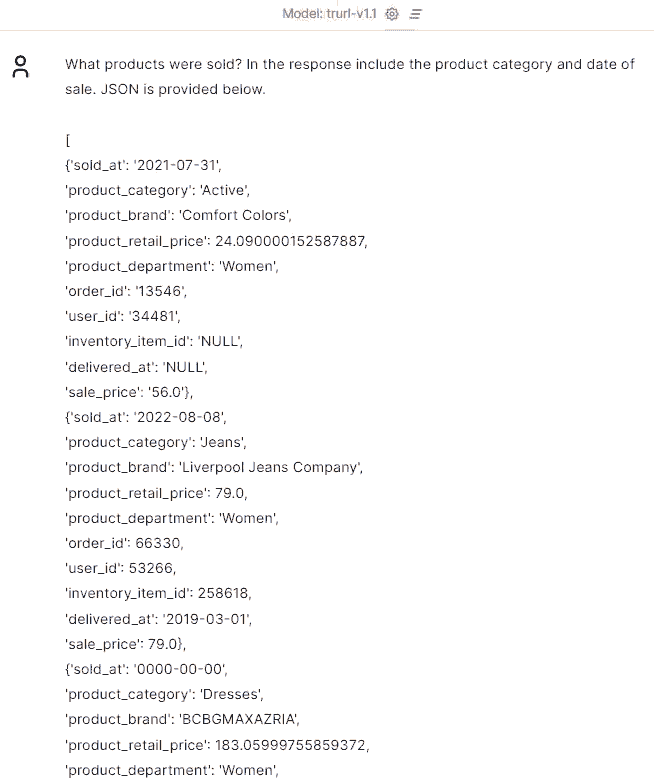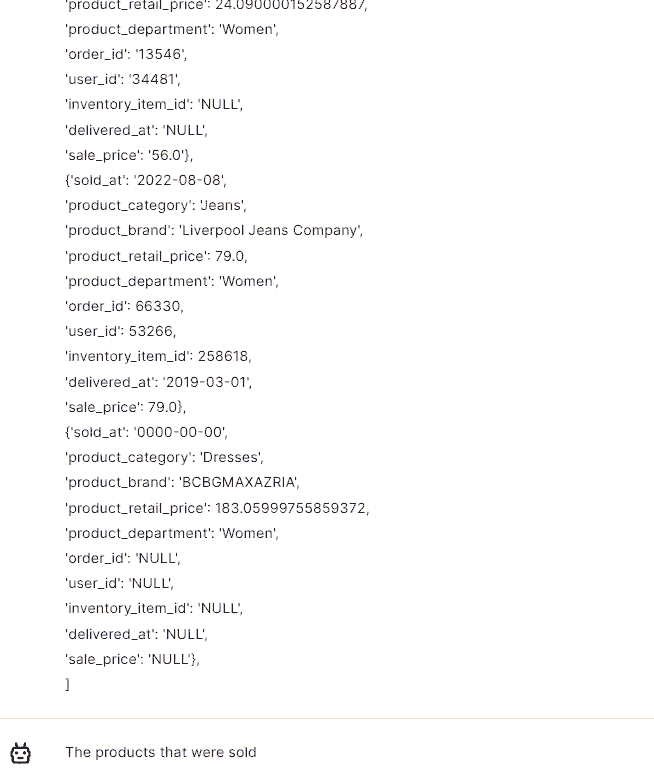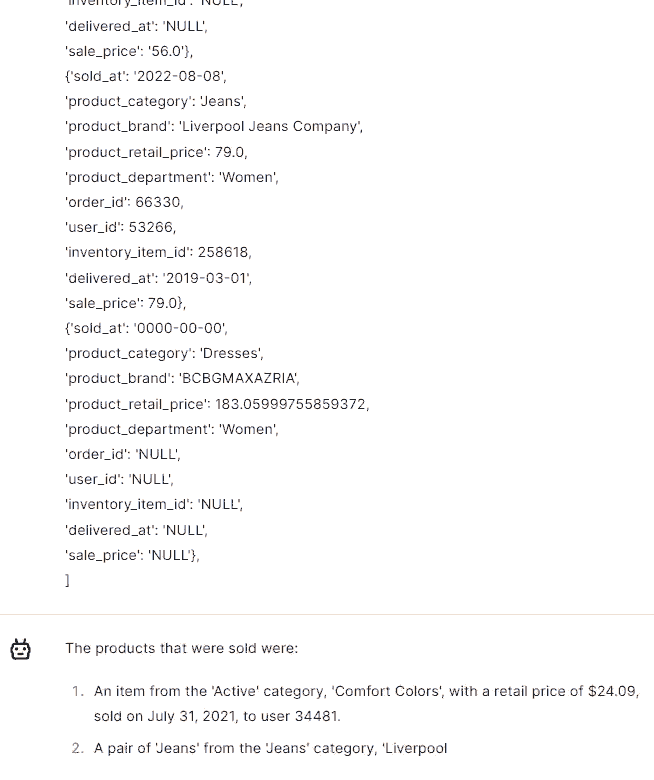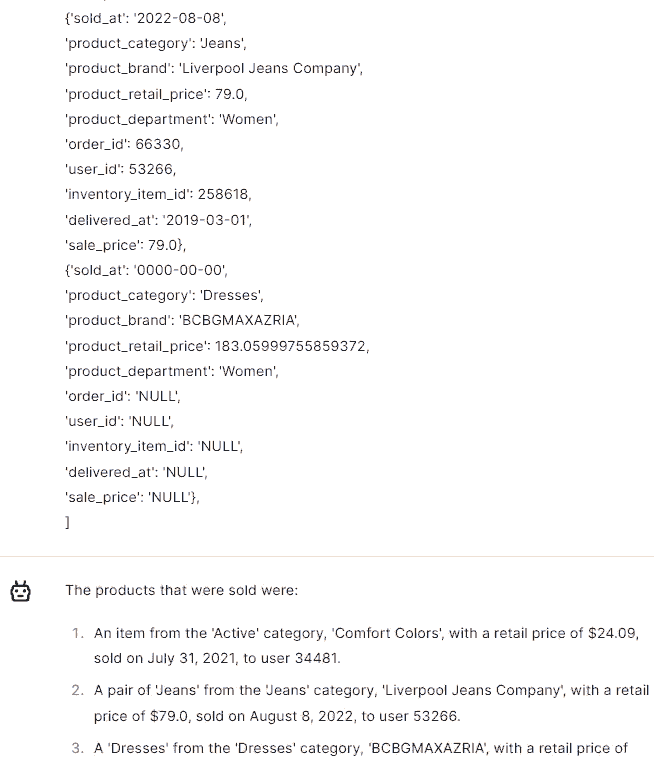
Summarization is invaluable, condensing only key information for efficient communication, saving time and enhancing productivity.
Trurl is able to efficiently summarize the content of conversations:
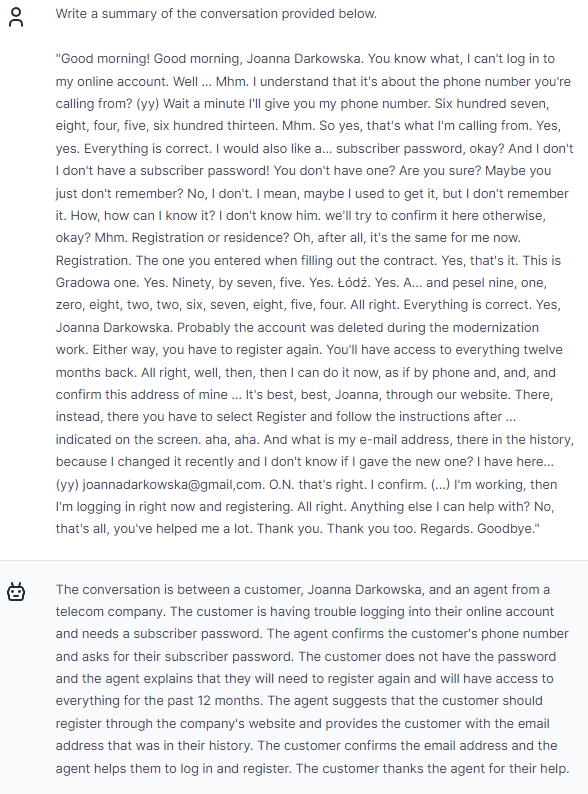
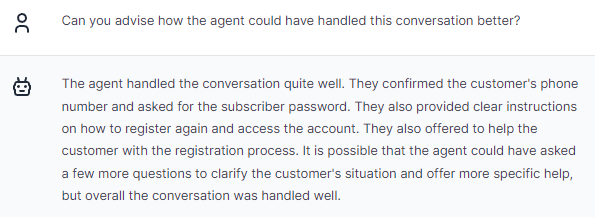
We can continue the conversation, ask further questions referring to the previous message.
Have you ever wondered why your customers contact you? Analyzing conversations and getting to know the most common reasons will give you valuable information about what they most often have problems with and what their expectations are.

Do you sometimes lack creativity? Let Trurl help you get your customers’ attention!
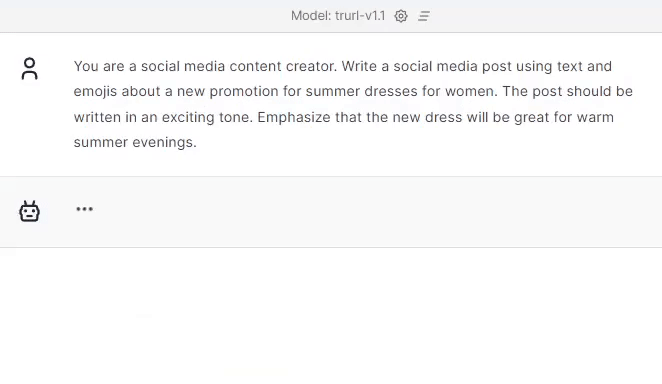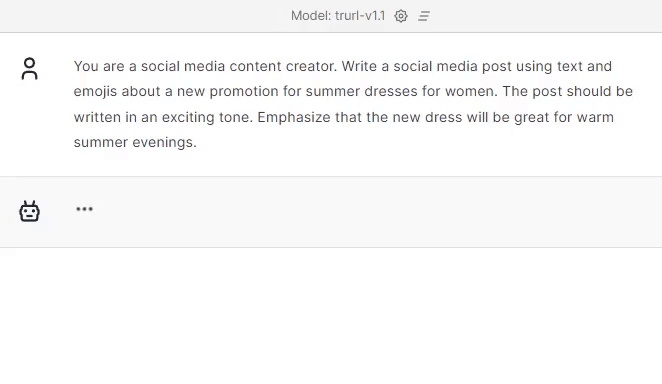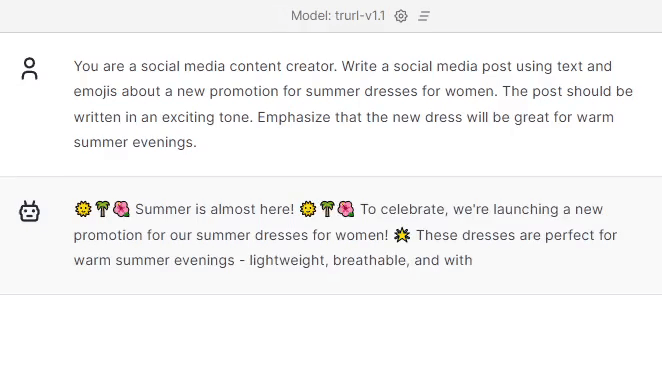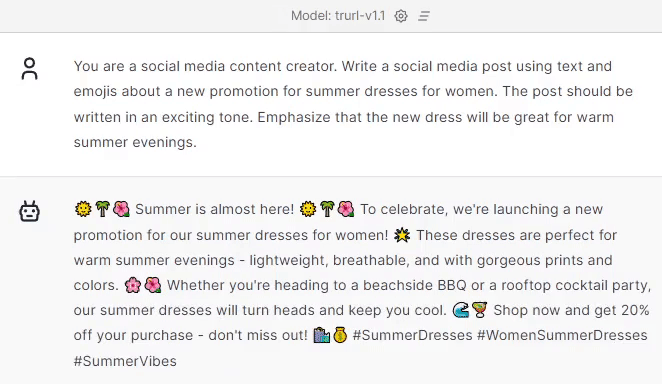
And way more! Contact us and we will build a model for you trained securely on your infrastructure & your dataset.
„Trurl is a robotic engineer, known from Stanislaw Lem’s novels „Cyberiad” and” Tales of the Robots „called a „constructor” with almost godlike abilities. In one of the stories, he creates a machine called „Elektrybalt”, which by description resembles today’s GPT solutions. We named the first Polish GPT model after the illustrious writer and his immeasurable imagination condensed into the character Trurl.
Author: Patrycja Biryło
Share

How should the agent argue to dispel all doubts of the buyer? Which arguments are the best and what is better not to mention? What are the most common refusal reasons?
With this informations, you will be able to respond to customer needs much better. Perhaps you will find out that the rules of the promotion are misunderstood or customers answer with a simple 'no’, to which it is best to tell them that they have the option of resigning from the service if it does not work for them…
The rest of the article is available on the link below: https://colab.research.google.com/drive/1wj8MJivIuNq04pBtPqW_FnCDfpgCnbWL#scrollTo=a14fba00
(NOTICE) In order to be able to use the notebook and send requests to our services, you have to upload a 'credentials.ini’ file to the runtime workspace (the main directory, next to sample_data folder). You can obtain one by getting in touch over at https://voicelab.ai/contact.
Author: Patrycja Biryło
Share

Are you having trouble dealing with all of the customer service required for your business to run? Or maybe it is simply taking too much time? Well, a very common choice is to develop a chatbot that will take the burden of your arms. However, it is not that simple. Building a good bot requires a great insight into your customer contacts and it is not an easy task to carry out manually. This notebook will show you how you can automatically extract a lot of useful data to help you achieve your goal of automated customer service.
The rest of the article is available on the link below: https://colab.research.google.com/drive/1wj8MJivIuNq04pBtPqW_FnCDfpgCnbWL#scrollTo=a14fba00
(NOTICE) In order to be able to use the notebook and send requests to our services, you have to upload a 'credentials.ini’ file to the runtime workspace (the main directory, next to sample_data folder). You can obtain one by getting in touch over at https://voicelab.ai/contact.
Author: Filip Żarnecki
Share

Your company is very prosperous, more deals are closed every single day. However, with great success come great responsibilities, one of which is customer service. You employ a lot of agents that handle contact with numerous clients. But a question arises.. which agents are the best at dealing with customers? Who is the most empathetic employee whose best practices, when spread across company, could boost the effectiveness significantly?
Let’s find out…
The rest of the article is available on the link below: https://colab.research.google.com/drive/1Nazvef5jfn3dFDiXIjwJacST5hsz9EFh
(NOTICE) In order to be able to use the notebook and send requests to our services, you have to upload a 'credentials.ini’ file to the runtime workspace (the main directory, next to sample_data folder). You can obtain one by getting in touch over at https://voicelab.ai/contact.
Author: Alicja Golisowicz
Share

It is not an easy task to identify what is really going on in our dialogues, especially when the volumes are big. But it would be extremely useful to quickly assess whether the client is the one causing trouble or the agent. Knowing this would allow to take targeted, knowledge-based actions that would solve problems much more quickly and cost-efficiently, not just shooting blanks hoping for a solution. How to achieve this?
Let’s find out..
The rest of the article is available on the link below:
https://colab.research.google.com/drive/1-4Q-xyHkCLDR7D-vDAVrkvmpHSRaFDgz
(NOTICE) In order to be able to use the notebook and send requests to our services, you have to upload a 'credentials.ini’ file to the runtime workspace (the main directory, next to sample_data folder). You can obtain one by getting in touch over at https://voicelab.ai/contact.
Author: Filip Żarnecki
Share

Have you ever wondered why your clients contact you? Do you have dialogs with your clients and wanted to easily detect the reason for contact and train your own model to detect it in your new data, based on previous interactions? You can easily use our reason for contact detection to annotate your data and train a model of your own.
Let’s find out how…
The rest of the article is available on the link below: https://colab.research.google.com/drive/1Nazvef5jfn3dFDiXIjwJacST5hsz9EFh
(NOTICE) In order to be able to use the notebook and send requests to our services, you have to upload a 'credentials.ini’ file to the runtime workspace (the main directory, next to sample_data folder). You can obtain one by getting in touch over at https://voicelab.ai/contact.
Author: Patryk Neubauer
Share

Often it’s hard to know what makes your clients react in one way or another. Some things related to the company or particular topics, might have particularly high impact on your clients – whether it’s negative or positive, it’s useful to know what causes it. Combining our Sentiment Classification and Intent prediction you can find out which client statements are of high impact.
The rest of the article is available on the link below:
https://colab.research.google.com/drive/1Imy844Mi5k9RCI5XICyfhfNhmu_nBwA4
(NOTICE) In order to be able to use the notebook and send requests to our services, you have to upload a 'credentials.ini’ file to the runtime workspace (the main directory, next to sample_data folder). You can obtain one by getting in touch over at https://voicelab.ai/contact.
Author: Patryk Neubauer