

Natural Language Processing
Generating paraphrases
Generating paraphrases

TRURL brings additional support for specialized analytical tasks:
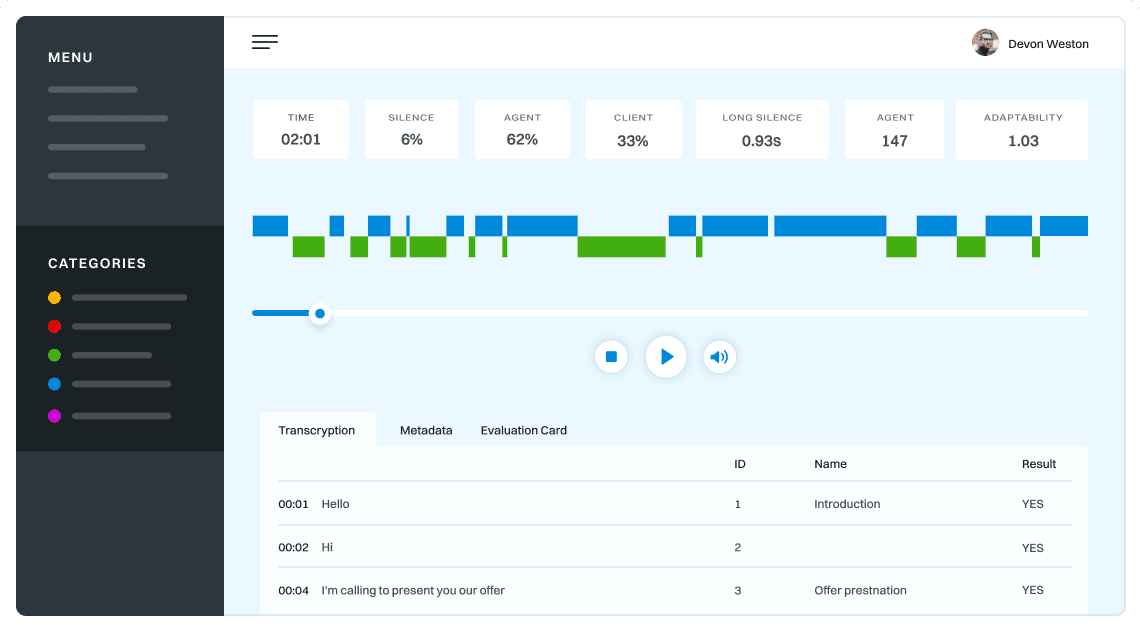
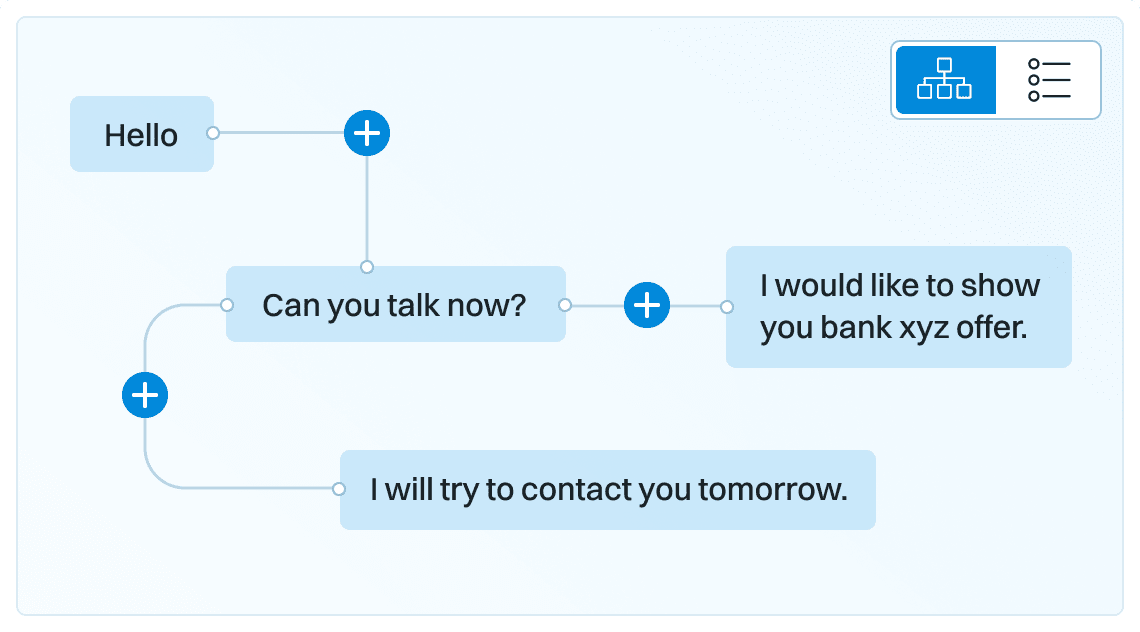
Dialog structure aggregation
Customer support quality control
Sales intelligence and assistance
TRURL can also be implemented effectively on-premise:
We will build a GPT model for you
Trained securely on your infrastructure
Trained on your dataset

Share

Today machine learning algorithms find more and more use cases which means we need more and more various data. Despite having big data centers with unbelievable amounts of information, there are still cases that require unique data. For example for some specific research purposes or few-shot learning tasks.
Few-Shot Learning is a type of machine learning problem when we only have a few samples of data for training. In this situation, MAML came to save the world. MAML stands for Model-Agnostic Meta-Learning.
Meta-Learning means learning the ability to learn. The goal is to prepare the model for fast adaptation. For example, instead of training the model of hundreds of dog images to recognize dogs, we teach our model to recognize the differences between images of animals. For instance, we could train the model to recognize different sizes of paws and ears, colors and shapes, for animal classification.
The idea behind the MAML method, invented by Chelsea Finn, Pieter Abbeel, Sergey Levine in 2017 [1], is to Meta-Learn on small tasks that leads to the fast-learning skill. Therefore, we can use it in situations when our amount of data is not enough for other methods. In this post, we will focus on MAML in NLP applications including few-shot text classification, but before that we need to make some clarification.
MAML is a method that creates steps by the following structure: make a copy of the used model for each task, then perform training on the support set, calculate loss on the query set, sum the losses, and backpropagate to end the loop. This method allows us to train models with low resources of data.
Meta-Task is the representation of data in the process of training. The original dataset is divided into smaller tasks that contains few or more samples so that the model is adapting to learn new classes based on few samples.
First of all, we wanted to test this method on two types of input to find the influence of its structure and performance on short and long text:

one short sentence,
several sentences.
In our case we trained and tested the method on two data sets, the first one was several sentences text about scientific areas with labeled field [2] and the second one was short sentence personal assistant commands with labeled intent 3].
From the data set with scientific areas named Curlicat we took 6 classes that clearly specify one area. Personal assistant data set contained 64 classes with 8954 samples. In our case, we used 16 classes with 10 samples per class with a focus on few-shot learning.
The previously mentioned data sets required some preprocessing for better results and to fulfill the used model requirements. For this reason, we removed duplicates and make sure that the text is no longer than 512 characters.
Finally, we split our data into Meta-Tasks which contains samples of support set and query set:
support set is a set that contains text with labels in order to learn,
query set is a set that contains text without labels in order to make prediction
Before final training, we spend some time looking for the best hyperparameters and find out that a few examples per Meta-Task gives the satisfying result and are ideal for few-shot-learning.
For the Curlicat data set, the training was made in two steps, firstly we trained our model on 4 classes with 100 samples per class and then made second training on 6 classes with 10 samples per class to check if the tested method can learn additional classes with few samples and avoid forgetting.
With the personal assistant data set, we made only one training on 16 classes with 10 samples per class, due to its simple structure.
The time we have to spend on training the model is difficult to estimate, due to the unstable nature of this method. However, the first stage is more predictable and repeatable and in our example, it took 2-3 hours to reduce the loss, but the second stage depends on the order of training samples can take from 1 hour up to 3-4 hours.
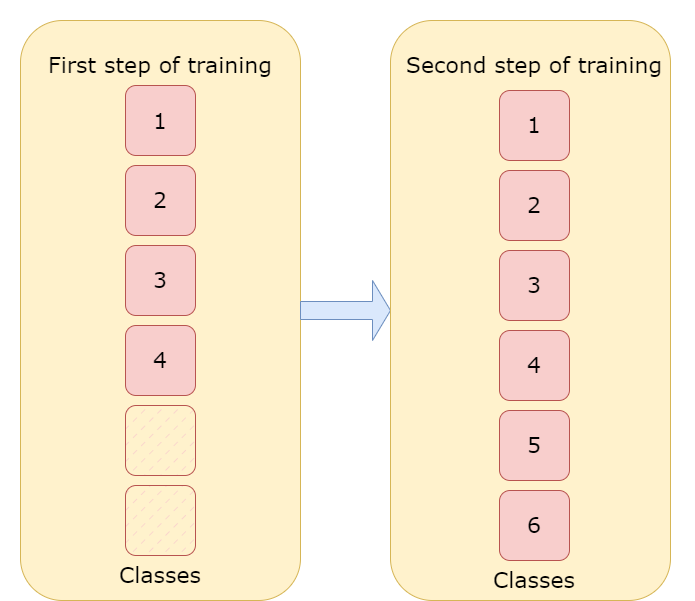
Additionally, each step had two stages. The method seems to be unstable in our case, despite low training loss, the validation prediction was very unstable, changing from 40% to 50% and then back to 40% or even 30%. To prevent this, we used stages. In the first stage, we are reducing training loss, saving the model for each epoch, but in the second stage, we are saving the model only if the F1 metric from the current epoch is better than F1 from the previous epoch. This solution let us train unstable methods to high prediction accuracy.
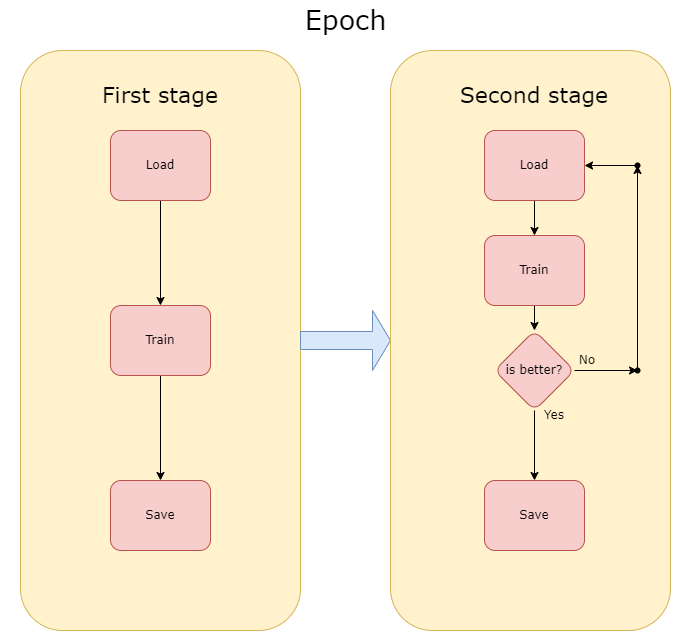
To show our results we used accuracy and F1 metrics. We tested the method on 100 samples per class in the first step and 300 samples per class in the second step. In the first step of training , we got 75% accuracy and 66.6% F1, the method successfully recognized 3 out of 4 classes. In the second step, the few-shot learning step, we got 83,3% accuracy and 77,8% F1 which is even better than the results from the first step and that leads us to a conclusion, we taught the model to learn. For the personal assistant data set with just one training on 16 classes with 10 samples per class, we got 70% F1 while testing it using only the second step which is a similar result to the Curlicat
One of the future adjustments can be changing the technique of adding new classes to the model. At this moment the place for new classes is reserved while creating the model which can lead to a situation when there won’t be a place for the new class. The solution is to make new places dynamically while adding new classes which can be done by modifying the classification layer, but while doing this we are losing our trained weights and that creates the need for second training with frozen weights which is very time-consuming.
This case gives us a clear view, that in some situations we don’t need thousands of records to successfully train models in machine learning and a few or a dozen samples can be enough. However, achieving high accuracy score can be challenging.
1. Chelsea Finn, Pieter Abbeel, Sergey Levine. ‘Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks’, 2017.
https://doi.org/10.48550/arXiv.1703.03400
2. Váradi, Tamás, Bence Nyéki, Svetla Koeva, Marko Tadić, Vanja Štefanec, Maciej Ogrodniczuk, Bartłomiej Nitoń, Piotr Pęzik et al. ‘Introducing the CURLICAT Corpora: Seven-Language Domain Specific Annotated Corpora from Curated Sources’. In Proceedings of the Language Resources and Evaluation Conference, 100–108. Marseille, France: European Language Resources Association, 2022.
http://www.lrec-conf.org/proceedings/lrec2022/pdf/2022.lrec-1.11.pdf.
Author: Szymon Mielewczyk

