

Natural Language Processing
Generating paraphrases
Generating paraphrases

TRURL brings additional support for specialized analytical tasks:
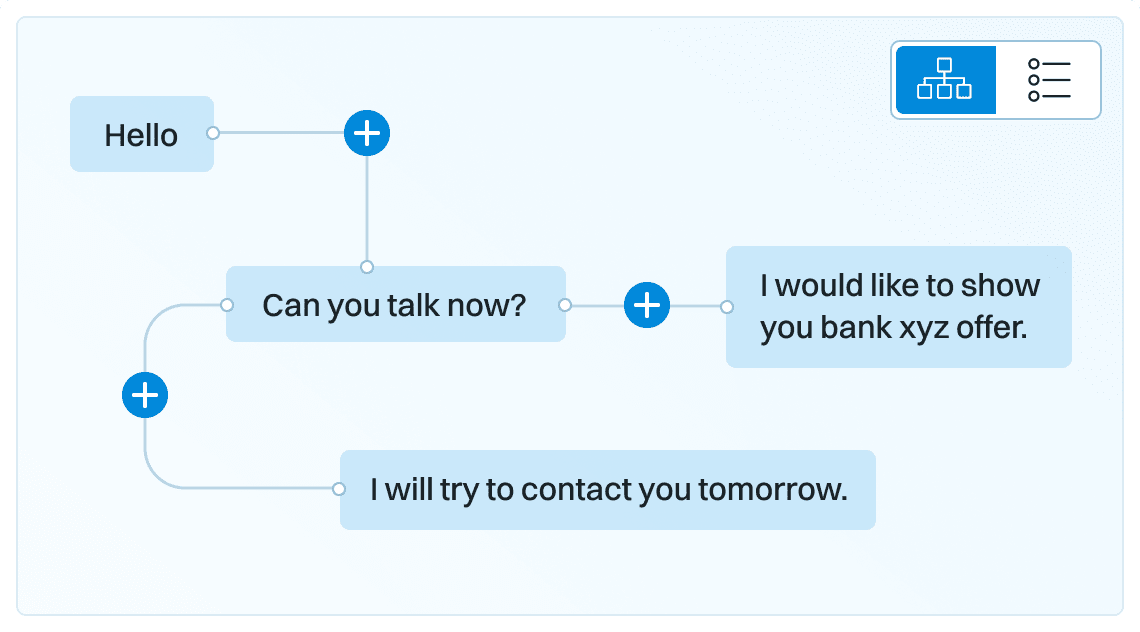
Dialog structure aggregation
Customer support quality control
Sales intelligence and assistance
TRURL can also be implemented effectively on-premise:
We will build a GPT model for you
Trained securely on your infrastructure
Trained on your dataset

Share
One of the crucial tasks in language understanding is topic modeling. Our highly abstract minds grasp topics quite easily. We naturally understand a conversation or written text context. But what exactly is a topic?
According to Cambridge Dictionary a topic is:
a subject that is discussed, written about, or studied.
Topic modeling focuses on preparing tools, models, or algorithms that might help discover what subject is discussed by analyzing hidden patterns. Those topics models are frequently used to find topics changes in the text, web-mining, or cluster the conversations. It is an excellent tool for information retrieval, quick large corpora summarization, or a method of feature selection. For instance, in Voicelab, we use topic modeling to categorize texts and transcripts quickly and discover inner patterns in conversations.
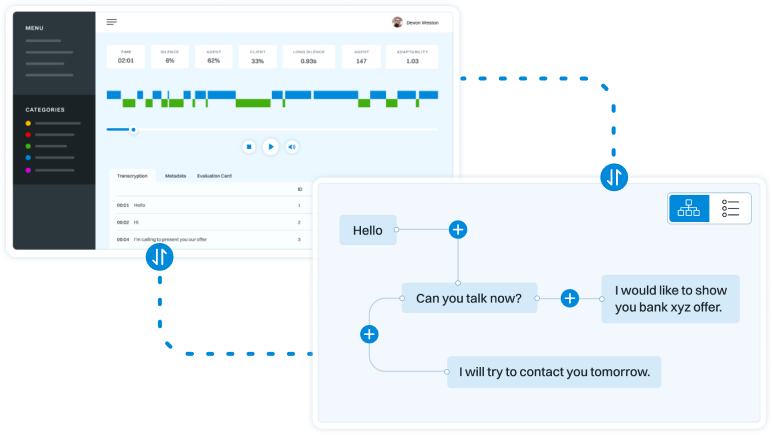
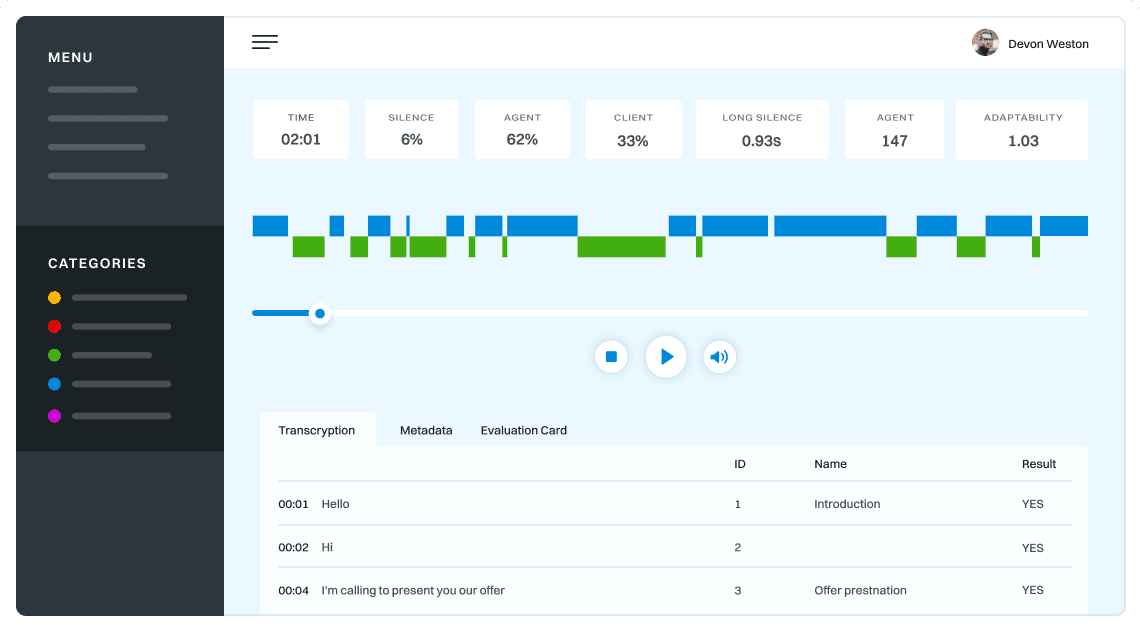
Below, there is an example of analysis of hundreds on conversations
with our topic sensitive kwT5 model.

However, to train such models, we need data. Lots of data. There are a few ways to approach this. Some experiment with supervised learning — but old-school supervised training requires manually labeled data. But some approaches don’t require annotated data (unsupervised learning). For instance, researchers tried to generate word or sentence embeddings using pretrained language models like BERTs or Word2Vecs and then to cluster them. Some used statistical methods like Latent Dirichlet Allocation (LDA) that represents documents as mixtures of topics that spit out words with certain probabilities. Others use approaches like KeyBert. KeyBert extracts document-level (or conversation-level) representations and uses cosine-similarity to compare them with the most similar words in the document. This allows for extracting key-phrases that are often closely related to the subject of discussion.
Those are nice but still not perfect. BERTs work great, but their pretraining process is not designed for topic modeling. And LDA is not that good with catching more difficult abstract concepts. Here is when the self-supervised approach comes to the rescue.
This type of learning uses unlabeled data and creates a pretext task to do. For instance, we can take a large corpus and try to predict the next word for a given sentence. Or we try to remove a single word and try to predict it. Usually, in each pretext task, there is part of visible and part of hidden data. The task is either to predict the hidden data or predict some property of the hidden data. So why not try to specify a pretext task closely related to the topic modeling?
The pretext task is the self-supervised learning task solved to learn meaningful representations, to use the learned representations or model weights obtained in the process, for the downstream task.
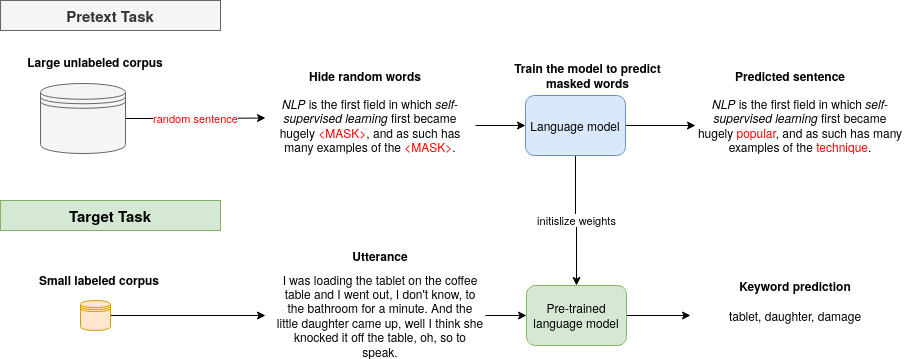
Learn more about pretext tasks here.
As we already know what a pretext task is, let’s focus on the topic-specific task for pretraining our NLP models. In 2019, an exciting model was proposed using Siamese BERT models for the task of semantic textual similarity (STS).
Semantic textual similarity analyzes how similar two pieces of texts are.
The paper uses a vast, open, and well-known text corpus available in multiple languages: Wikipedia. Wikipedia articles are separated into sections that focus on specific aspects. Hence, sentences in the same section are thematically closer than sentences in different sections. This means that we can easily create a large dataset of weakly labeled sentence triplets:

The anchor (base sentence)
The positive example coming from the same section
The negative example from a different section
All examples in a single sample should come from the same article.
For instance, let’s look at a NLP article in Wikipedia.
Let’s take an anchor from the History section:
Up to the 1980s, most natural language processing systems were based on complex sets of hand-written rules.
And now, randomly select a positive example from the same, History section:
In the 2010s, representation learning and deep neural network-style machine learning methods became widespread in natural language processing.
Now, one random sentence from other section Methods: Rules, statistics, neural networks, but still, the same article:
A major drawback of statistical methods is that they require elaborate feature engineering.
We can generate thousands of unique examples using less than thousands of articles for any available language on Wikipedia. As Voicelab.ai is a Polish company, we decided to go on with the Polish language and Polish Wikipedia.
We want to modify the model’s parameters so that the representation generated for sentences from the same topic are more similar than those from other discussions. Hence, what we are trying to do next, is:
make a representation of an anchor and positive example more similar
make a representation of an anchor and negative example less similar
And this is precisely what a triplet loss do.
Triplet loss is a loss function for machine learning algorithms where a reference input (called the anchor) is compared to a matching input (called positive) and a non-matching input (called negative). The anchor to positive example distance is minimized, and the distance from the anchor to the negative input is maximized.
To summarize, here are the steps:
get samples: one sample consists of an anchor, positive example and negative example
generate representations for each sample with the model (e.g., BERT)
calculate (e.g., cosine or Euclidean) distance between an anchor and positive example, and between an anchor and negative example
with triplet loss minimize distance between an anchor and positive example and maximize between an anchor and negative example
We can simply compare embeddings with `TripletMarginWithDistanceLoss` from PyTorch.
As we know and understand how SentenceBert and Triplet Loss work, we can dive into coding. First, let’s download the latest Wikipedia dump. Then we have to prepare data triplets. We have to load Wikipedia articles and divide them into sections. Then, we have to make a list of sentences for each section. Finally, we can prepare a torch dataset. The pseudocode for the dataset is presented below.
class WikiTripletsDataset(Dataset):
def __init__(self, data_path):
with open(data_path) as json_file:
wiki_json = json.load(json_file)
triplets = list()
for article in wiki_json:
# get random section from one article
anchor_section_nr, negative_section_nr = get_section_nr(article["sections"])
# get random sentence from selected sections
anchor, positive, negative = get_senctence_from_section(anchor_section_nr,
negative_section_nr,
article["sections"])
triplets.append([anchor, positive, negative])
self.samples = triplets
def __len__(self):
return len(self.samples)
def __getitem__(self, idx):
return self.samples[idx][0], self.samples[idx][1], self.samples[idx][2]
The next step is model preparation. In the constructor, we have to define model parts: here, we use the `transformer` model from hugging face for representation’s generation (`self.model = AutoModel.from_pretrained(model_path)`). We additionally add a regularizer in the form of the `dropout`, to prevent overfitting. As we’re tokenizing data during the training instead in the dataset, we have to define tokenizer: `self.tokenizer = AutoTokenizer.from_pretrained(model_path)`. Let’s look at our PyTorch code:
class SentenceBertModel(pl.LightningModule):
"""Sentence Bert Polish Model for Semantic Sentence Similarity"""
def __init__(self, model_path):
super().__init__()
self.model = AutoModel.from_pretrained(model_path).cuda()
self.tokenizer = AutoTokenizer.from_pretrained(model_path)
self.triplet_loss = nn.TripletMarginWithDistanceLoss(
swap=True, margin=1)
self.dropout = nn.Dropout(p=0.2)
def forward(self, sentence, **kwargs):
# tokenize sentence
tokens = self.tokenizer(
list(sentence), padding=True, truncation=True, return_tensors='pt')
# pass through the transformer model
x = self.model(tokens["input_ids"].cuda(),
attention_mask=tokens["attention_mask"].cuda()).pooler_output
x = self.dropout(x)
return x
We use pytorch_lightning for easier ML pipeline. The framework was designed for professional and academic researchers working in AI. As the authors say: „PyTorch has all you need to train your models; however, there’s much more to deep learning than attaching layers.” Hence, when it comes to the actual training, there’s a lot of boilerplate code that we need to write, and if we need to scale our training/inferencing on multiple devices/machines, there’s another set of integrations we might need to do.
Here is an example training step presented for the SentenceBert. First, we get a new batch of data straight from our dataset. Then, we pass the data to the `forward()` function. Everything in the `forward` happens, and we get back out representations. We compare embeddings with `TripletMarginWithDistanceLoss` from PyTorch.
def training_step(self, batch, batch_idx):
anchor, positive, negative = batch
# generate representations
anchor_embedding = self(anchor)
positive_embedding = self(positive)
negative_embedding = self(negative)
# calculate triplet loss
loss = self.triplet_loss(
anchor_embedding, positive_embedding, negative_embedding)
return {'loss': loss}
def validation_step(self, batch, batch_idx):
anchor, positive, negative = batch
# generate representations
anchor_embedding = self(anchor)
positive_embedding = self(positive)
negative_embedding = self(negative)
# calculate triplet loss
loss = self.triplet_loss(
anchor_embedding, positive_embedding, negative_embedding)
self.log("validation_loss", loss)
Now we just need to run the training and wait.
import argparse
from torch.utils.data import DataLoader
import pytorch_lightning as pl
from dataset import WikiTripletsDataset
from model import SentenceBertModel
def get_args_parser():
# arguments
return parser
def main(args):
# load custom datasets
train_dataset = WikiTripletsDataset(args.train_path)
val_dataset = WikiTripletsDataset(args.test_path)
# pack data in batches
dataloader_train = DataLoader(train_dataset, shuffle=True, batch_size=args.batch_size,
num_workers=args.workers, drop_last=False)
dataloader_val = DataLoader(val_dataset, shuffle=False, batch_size=args.batch_size,
num_workers=args.workers, drop_last=False)
# define model
model = SentenceBertModel(model_path=args.model_path)
# set trainer
trainer = pl.Trainer(max_epochs=args.epochs)
# run training
trainer.fit(model, dataloader_train, dataloader_val)
if __name__ == '__main__':
parser = get_args_parser()
args = parser.parse_args()
main(args)
Finished! Now your model is ready to use. If you don’t want to train the SentenceBert yourself, you can use our Polish SentenceBert model, which is available here.
Share
Author: Agnieszka Mikołajczyk

