

Natural Language Processing
Generating paraphrases
Generating paraphrases

TRURL brings additional support for specialized analytical tasks:
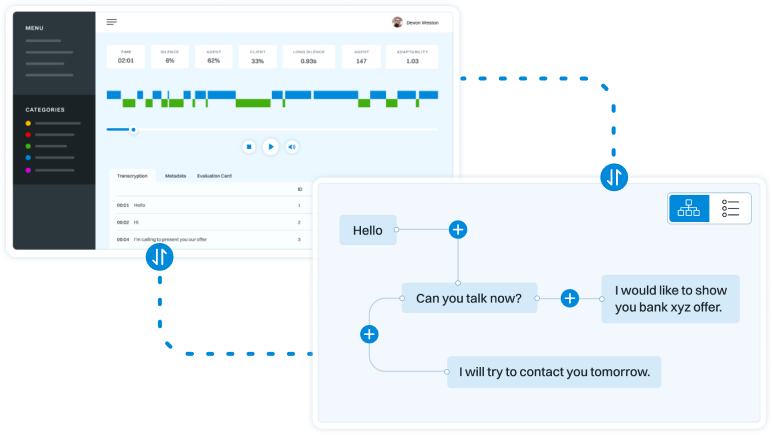
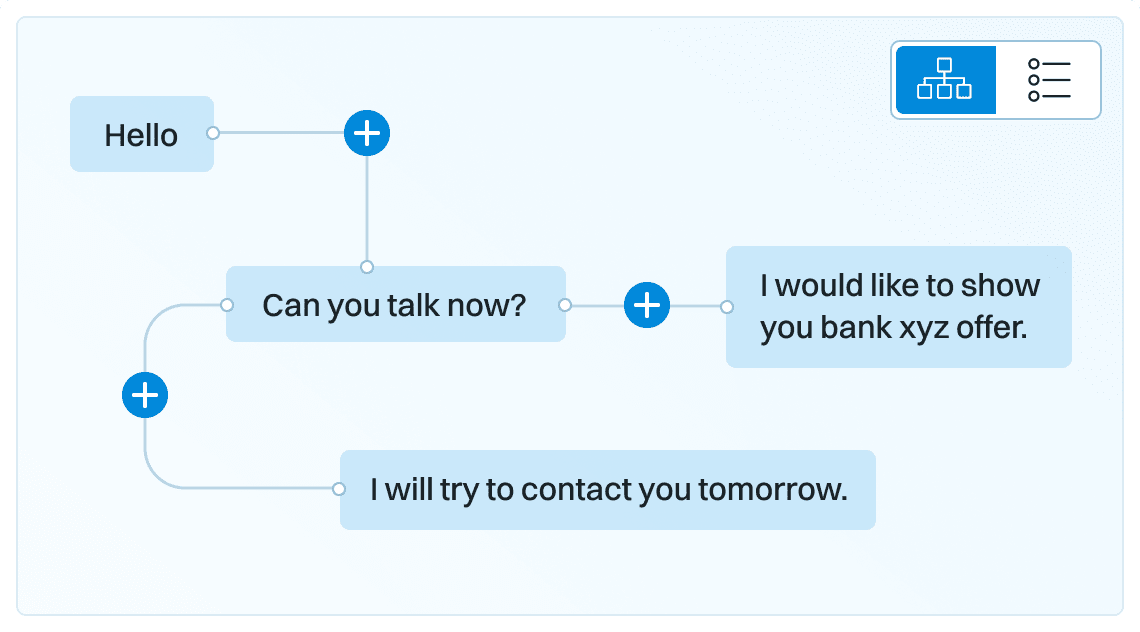
Dialog structure aggregation
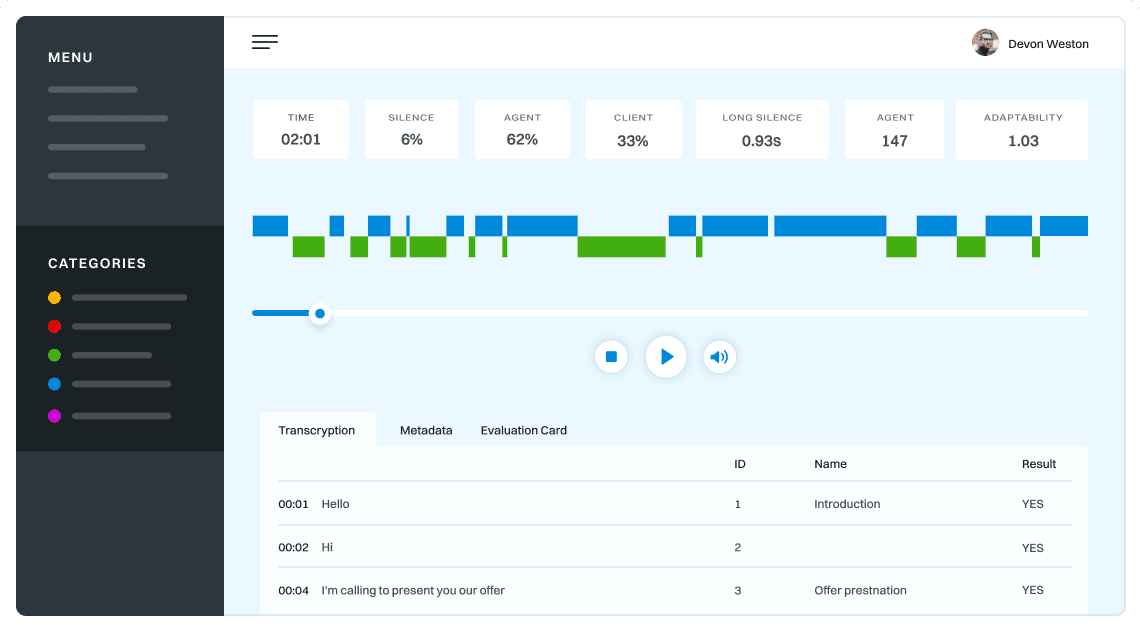
Customer support quality control
Sales intelligence and assistance
TRURL can also be implemented effectively on-premise:
We will build a GPT model for you
Trained securely on your infrastructure
Trained on your dataset

Share
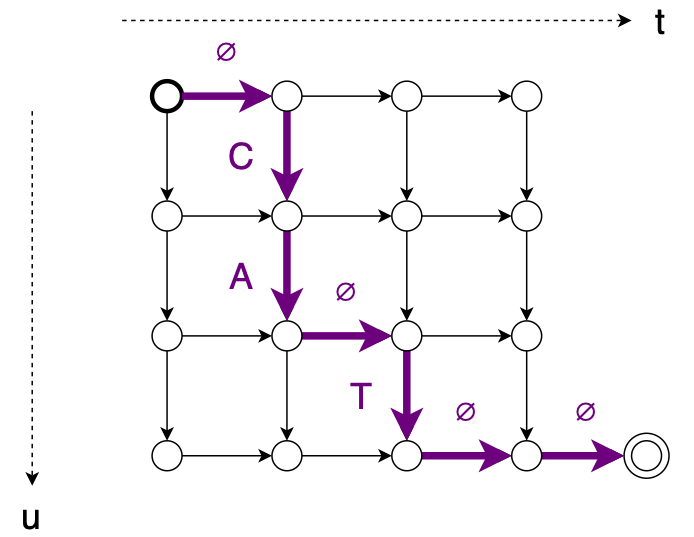
Connectionist Temporal Classification(CTC)(link) is one of the most popular criterion in Speech Recognition. It brings both good performance and training simplicity, but one of main disadvantages is conditional independence of labels. Another one is requirement for input to be longer than output. RNN Transducer (RNNT)(link) was proposed to overcame those issues. New loss function expands CTC mechanisms – blank label and time-restricted alignment, presents some new improvements, and removes inconveniences.
To address first problem, RNNT introduces new model architecture consisting of Predictor Network combined with Encoder Network in Joiner Network.

Encoder behaves as acoustic model – produces latent representation of acoustic features. Predictor consumes sequence of text tokens, thus can be seen as inner Language Model. Joiner sums both modules outputs and proceeds with simple feedforwad layer transforming latent representation to output labels probability distribution. The main idea is to support acoustic part of speech recognition with lexical dependencies built on recognition history. Both Encoder and Predictor network can be transferred from pretrained models – CTC, CE or other tasks, like wav2vec, can be utilized as Encoder while Predictor can be initialized with Neural language Model. RNNT operates in time and labels space, thus allows multiple outputs for single input, which solves second problem.
Incorporating Predictor Network can be beneficial not only in terms of modeling capability. Since Predictor operates purely on text input, it can be easily pretrained on large amount of data. Predictor can also be adapted to new domain using this mechanism (link, link). In contrast to audio, large amount of text data suitable for training are easily available. It also allows to make use of user data, ie on contact list on mobile device. Such single module adaptation can be performed directly on device, assuring privacy.
Unlike standard Attentions models, RNNT can run in streaming fashion, even on mobile devices (link). Seq-2-Seq models tend to relay on full input sequence. It is possible to restrict their inference to current(or contexted) input, but it has impact on performance. In contrary, RNNT itself does not model time dependencies, thus can run in streaming fashion out of the box. Forcing Seq-2-Seq models may also bring noticeable delay into system. RNNT model latency can be controlled in multiple ways – with loss function restrictions utilizing alignments (link) or forcing monotonic outputs, decoding strategies (link) or auxiliary losses (link). RNNT seems to work well with wordpieces outputs (link, link), which helps to keep good realtime and computational complexity by reducing output steps number.
With all this features come some drawbacks. The most severe one is training memory consumption. Since acoustic and text representation can vastly differ in length, they cannot be simply added. We can combine two 3D matrices using broadcasting, but it forces huge memory overhead due to spare paddings (link). Keep in mind it’s only forward pass, we need to keep parameters for backpropagation as well. Alongside common ways of reducing memory footprint, like using half precision or training using examples sorted by length, some new techniques were proposed. Broadcasting was replaced with per utterance combination (link) followed by concatenation, so there is no extra padding added to shorter examples. The same article utilizes merging softmax function into loss computation, which can save extra memory when using large amount of wordpieces. Recently k2 project team put their effort to optimize RNNT memory footprint. They implement some of already proposed solutions (Recurrent Neural Aligner – restricted varaint of RNNT so it can emit only one symbol per frame), as well as some new ideas, like pruned RNNT. This approach minimizes memory usage by pruning zero gradients from backproagation.
Also predictor can introduce some exposure bias to model – training on small amount of data may lead to overfitting and generalization issues. Some methods to prevent this aim directly at training procedure (link), while other propose architecture changes (link) or training pipeline tricks (link). With all mentioned above, RNNT models can be challenging to train and diagnose.
Despite problems, RNNT seems to gain more and more attention, and list of frameworks offering RNNT keeps growing. Here are some of them:

NeMo (link)
SpeechBrain (link)
PyTorch (link)
k2 (link)
ESPnet (link)
There are some standalone implementations offering bindings to popular libraries like PyTorch or Tensorflow (link). Surprisingly, there is no official implementation in Tensorflow, despite Google seems to put some effort in RNNT development (link). Efficient RNNT implementations from k2 are available as separate modules (link).
Combining all together, we think RNNT can lead to further speech recognition improvements. Incorporating lingual aspect directly into acoustic model may boost generalizing abilities, especially in challenging acoustic conditions. Predictor adaptation using only text data may be easy way dealing with new/out of domain data. Keep in mind, that so far we only considered ASR systems without external Language Model. While in conventional systems, Language Model integration is quite straightforward, RNNT offers few strategies of fusion, like deep, shallow or cold. (link)
It seems that RNNT can lead to SOTA results in some products, like mobile devices systems or streaming applications. Modular design allows to use pretrained Encoder and Predictor networks as single pipeline in end-to-end manner and greatly simplify speech recognition system. With more attention from research teams, RNNT will improve in field of memory footprint, training stability and overall performance.
Share
Author: Jakub Filipiuk

