

Natural Language Processing
Generating paraphrases
Generating paraphrases

TRURL brings additional support for specialized analytical tasks:
Dialog structure aggregation
Customer support quality control
Sales intelligence and assistance
TRURL can also be implemented effectively on-premise:
We will build a GPT model for you
Trained securely on your infrastructure
Trained on your dataset

Share
In recent years, deep learning-based Text-To-Speech systems outperformed other approaches in terms of speech quality and naturalness. In 2017, Google proposed the Tacotron2 end-to-end system capable of generating high-quality speech approaching the human voice. Since then, deep learning synthesizers have become a hot topic. Many researchers and companies have published their Tacotron2 based end-to-end TTS architectures like FastPitch and HifiGan.
Besides the ongoing research about few-shot TTS models, top architectures still require relatively large datasets to train. Moreover, both spectrogram generators and vocoders are sensitive to errors and imperfections of the training data.
There are datasets within the public domain, such as LJSpeech and M-AILABS. However, only a few of them provide good enough quality, especially in languages other than English.
In this article, we will present our approach to building a custom dataset designed for a deep learning-based text-to-speech model. We will explain our methodology and provide tips on how to ensure high-quality of both transcriptions and audio.
We split it into two parts. The first one will focus on the text and provide data on where to get and how to prepare transcriptions for recording. The second part will mainly cover recording and audio processing.
Keep in mind that there are differences between languages. Some of our findings might not apply to all of them.
First things first, we need to have a source of our text data. The easiest to get and probably the most commonly used sources of text are open domain books.
While we agree that they’re a great source, there are few things to consider:

Many public domain books are old, which might cause transcriptions to be archaic, especially in languages that changed over the years.
They may be lacking difficult words and have little variety (e.g. children’s books).
They might have insufficient punctuation (e.g. there are very few questions in nature books).
Since TTS models learn to map n-grams to sounds, if the dataset lacks some of them (which might be caused by 1 or 2), the model will have problems with their pronunciation. It will be especially noticeable in words with difficult or unique pronunciation (this is often called phoneme coverage). The third might cause problems like not stressing questions or strange behaviour when facedSchodowski with a lot of punctuation – e.g. when enumerating.
Therefore, to ensure good phoneme coverage and a sufficient amount of punctuation, we recommend diversifying the sources of transcriptions.
Each source and genre has its characteristics that we should consider when building a dataset. For example, interviews on average have significantly more questions than news outlets or articles about nature do. Dialogue-heavy stories have more interpunction. Scientific papers will more often have an advanced vocabulary. The press will probably require more normalization (more on that later), some sources might have a lot of foreign words (which we want to avoid), and so on.
If we intend to use our TTS model for something more specific, adding transcriptions that have domain-specific words may also improve the result.
How can we find out how many hours of data we will have from collected text? For that we will need speech rate. Speech rate is the number of words spoken in 1 minute, and the average speech rates are relative to context and language.
Presentations: between 100 – 150 wpm for a comfortable pace
Conversational: between 120 – 150 wpm
Audiobooks: between 150 – 160 wpm, which is the upper range for people to comfortably hear and vocalise words
Radio hosts and podcasters: between 150 – 160 wpm
Auctioneers: can speak at about 250 wpm
Commentators: between 250- 400 wpm
Source
As you can see, the best speech rate for the general use TTS system is around 150 words per minute. The LJSpeech speech rate is approx. 140 wpm. Of course, you should consider your speakers’ natural speech rate to ensure they sound authentic.
After finding the perfect speech rate, the length dataset can be estimated with the following python script.
import os
DIR_PATH = '/path/to/transcriptions/' # Path to the directory with our transcriptions
SPEECH_RATE = 120 # Speech rate (words per minute)
transcriptions = {}
word_count = 0
for current_path, folder, files in os.walk(DIR_PATH):
for file_name in files:
path = os.path.join(current_path, file_name)
with open(path) as transcription_file:
transcription = transcription_file.read()
for punct in string.punctuation:
transcription = transcription.replace(punct, ' ') # Replace punctuation with whitespaces
transcription = re.sub(' {2,}', ' ', transcription) # Delete repeated whitespaces
transcriptions[path] = len(transcription.split())
word_count += transcriptions[path]
print(f"There are {word_count} words in total, which is around {word_count/SPEECH_RATE} minutes.")
It simply sums the number of words in every transcript and divides that number by your estimated speaker’s speech rate.
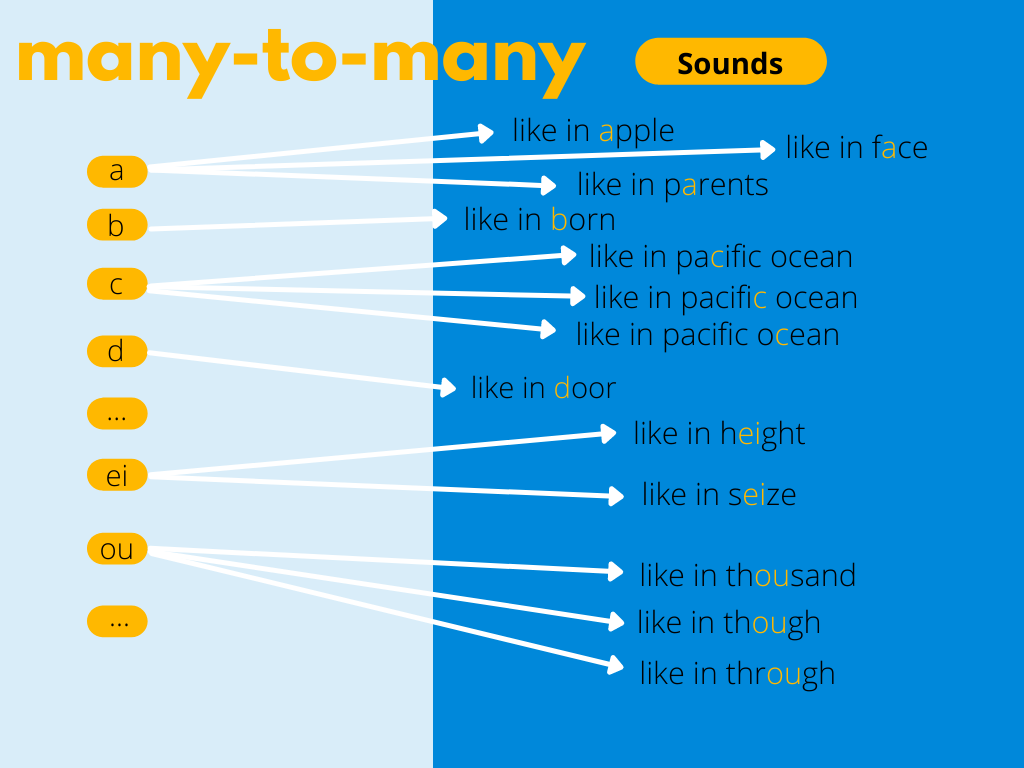
It is useful to think of text-to-speech synthesis as a mapping many-to-many problem. We want our model to learn how to change letters into sounds, hence the size of the space of all possible mappings between phonemes/letters and sounds is important. As mentioned before, a spectrogram generator without a phonemizer may perform better on the Polish dataset than its English version of the same size. It seems easier to train a TTS model for languages like Polish or Spanish, whose orthographic systems come closer to being consistent phonemic representations.
Presented below visualisation of many-to-many problem for English TTS.
To minimize the number of mappings between characters and sounds, we should normalize our dataset. After this step, it should contain only the words and punctuation we need to verbalize digits and abbreviations, write numbers with words and expand abbreviations into their full forms.
| Raw | Normalized |
| David Bowie was born on 8 Jan 1947. | David Bowie was born on eighth January nineteen forty-seven. |
| Bakery is on 47 Old Brompton Rd. | Bakery is on forty-seven Old Brompton Road |
Moreover, we need to take care of borrowings, words from other languages, which may appear in our texts. Borrowings should be written as you hear them.
| Raw | Normalized |
| She yelled – Garçon! | She yelled – Garsawn! |
| Causal greeting in Polish is “cześć”. | Casual greeting in Polish is “cheshch”. |
Of course, you can restrain from doing that if you don’t have any borrowings in your dataset or if you enforce a specific way of reading on speakers, but for their comfort and simplicity, it is better to just write borrowings as you hear them.
Another problematic part of language normalization is acronyms. In our dataset, we decided that acronyms that are read as letters will be split with ‘-’.
| Raw | Normalized |
| UK | UK |
| OPEC | OPEC |
As in the example above, OPEC is read as a word, not as letters, therefore we don’t need to split it. The last tip on normalization is to choose a symbol set. That allows us to filter out unwanted symbols, as it will make the further stages of processing easier and simpler.
After text collecting and processing, it’s time to record and form our brand-new dataset.
Share
Authors: Marcin Walkowski, Konrad Nowosadko, Patryk Neubauer
Next in the series: How to prepare a dataset for neural Text-To-Speech — Part 2: Recordings & Audio Processing

