

Natural Language Processing
Generating paraphrases
Generating paraphrases

TRURL brings additional support for specialized analytical tasks:
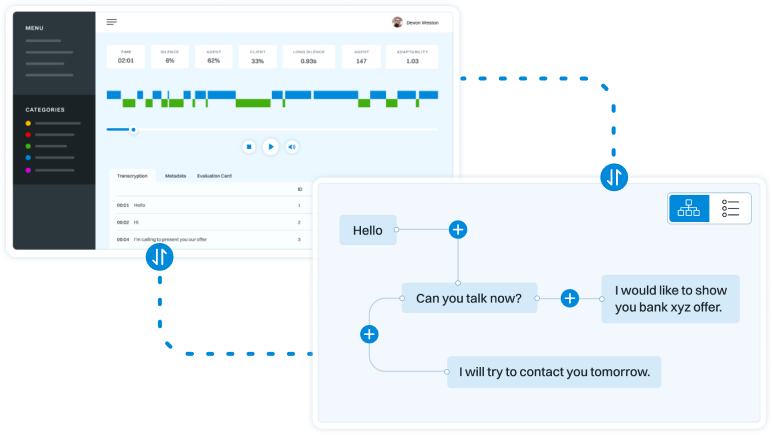
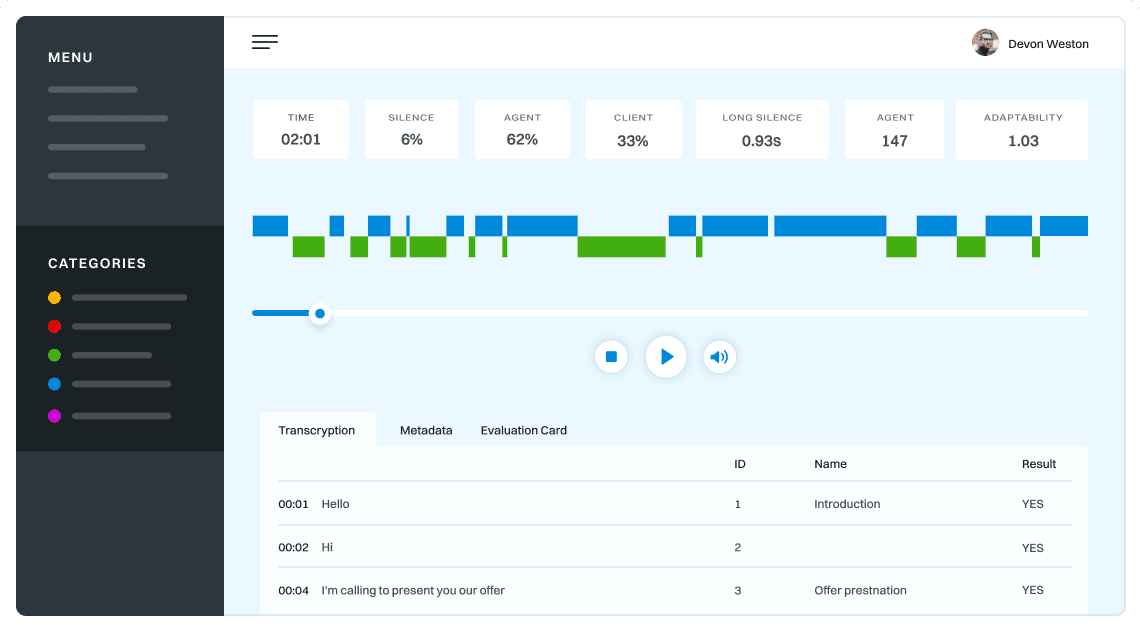
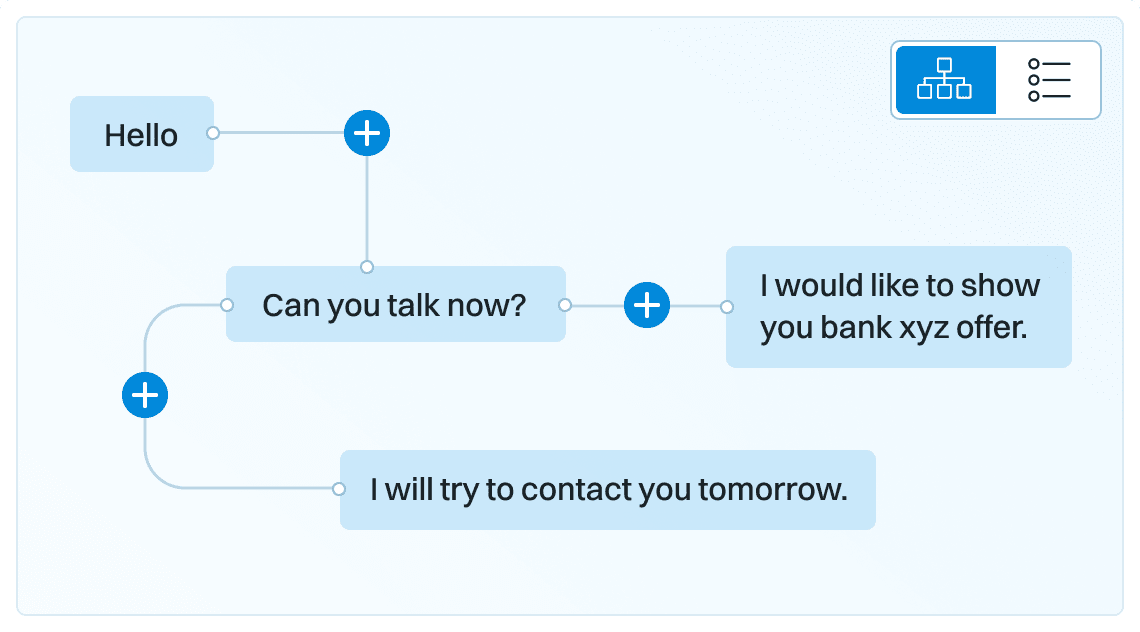
Dialog structure aggregation
Customer support quality control
Sales intelligence and assistance
TRURL can also be implemented effectively on-premise:
We will build a GPT model for you
Trained securely on your infrastructure
Trained on your dataset

Share

Our NLP Team at Voicelab in cooperation with the University of Lodz prepared one of the challenges at Poleval 2021.
PolEval is a set of annual ML challenges for Polish NLP, inspired by SemEval. Submissions compete against one another within certain tasks selected by organizers, using available data, and are evaluated according to pre-established procedures.
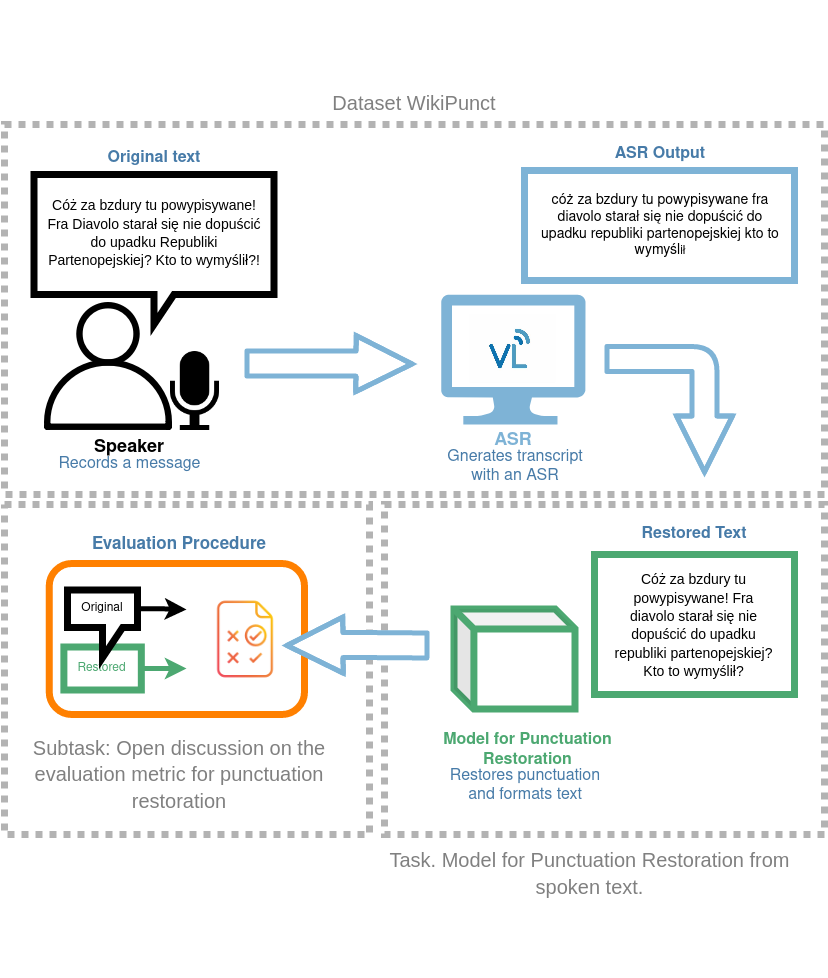
The purpose of our Task 1: Punctuation restoration from read text is to restore punctuation in the ASR recognition of texts read out loud. Along with the Task we shared the dataset and WikiPunct, consisting of over 1500 recordings and 32,000 texts. WikiPunct is a crowdsourced text and audio data set of Polish Wikipedia pages read aloud by Polish lectors. The dataset is divided into two parts: conversational (WikiTalks) and information (WikiNews). Over a hundred people were involved in the production of the audio component. The total length of audio data reaches almost thirty-six hours, including the test set. Steps were taken to balance the male-to-female ratio.
Read more about the data and the task here. Data has been published in the following repository (repository). Gold-standard test data annotation has been published in the „secret” branch.
Come and see us on 25th October at the NLP day conference on the PolEval track. First, we will introduce our Task, and the four first winners will describe their approaches.
As an official Partner, we invite you to register for the AI & NLP conference with our unique promo code: FREE524, which will give you free access to all presentations during the first two days of the conference.
Share

