

Natural Language Processing
Generating paraphrases
Generating paraphrases

TRURL brings additional support for specialized analytical tasks:
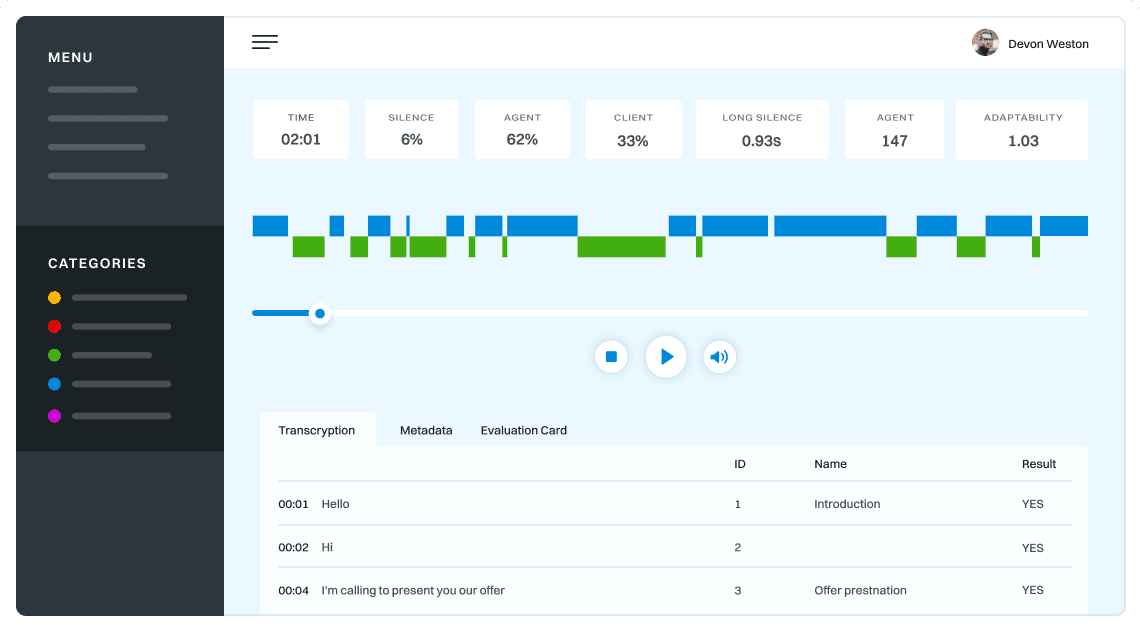
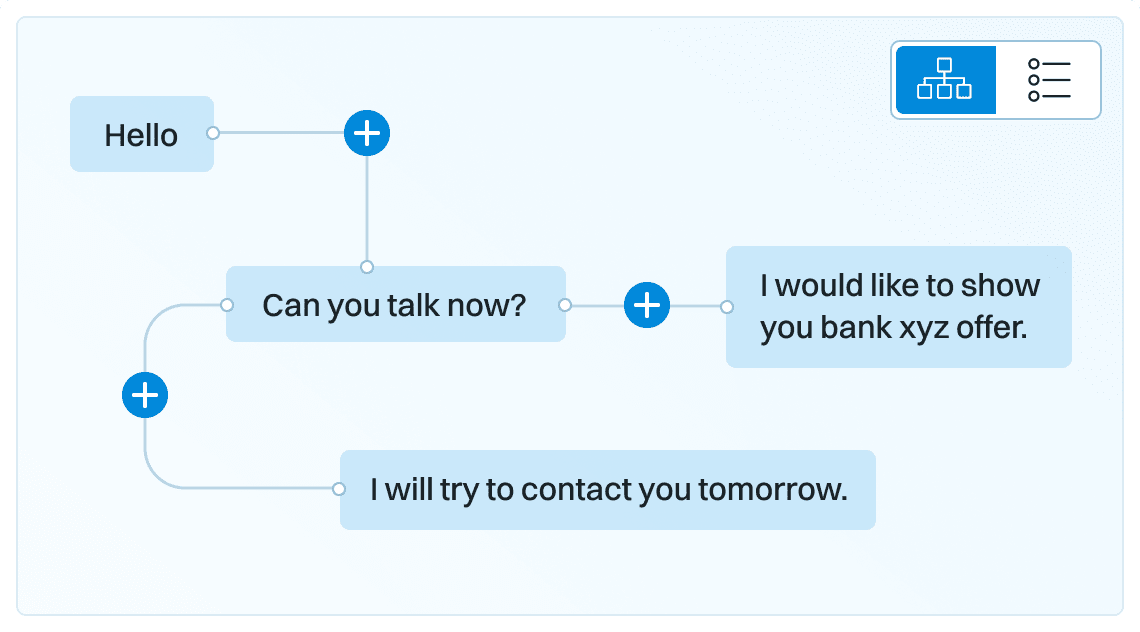
Dialog structure aggregation
Customer support quality control
Sales intelligence and assistance
TRURL can also be implemented effectively on-premise:
We will build a GPT model for you
Trained securely on your infrastructure
Trained on your dataset

Share

Pfeiffer et al. (https://arxiv.org/pdf/2007.07779.pdf)
The present language models like T5 or Bert are huge. The base version of T5 is reaching up to 220 million parameters and hundreds of megabytes of memory. Imagine how much time and resources-consuming is training a model like this. Fortunately, there is an idea of Transfer Learning, which means that authors – usually big tech companies and research centers – share their trained models. Everyone can easily download a pre-trained model and fine-tune on a specific task.
An alternative to fine-tuning is the idea of small task-specific layers called adapters. Adapter modules are characterized by compactness weighting from 0.2 to 4% of model size.
On the graph below we can clearly see that adapters perform as well as fine-tuning top layers despite having two orders of magnitude less parameters. Y axis at level 0 shows the performance of a fully fine-tuned model (all layers, not only the top layers).
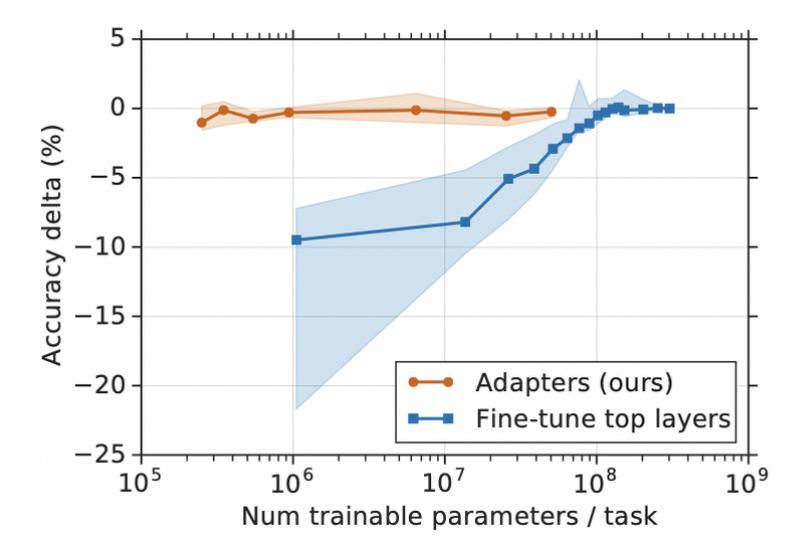
Houlsby et al. (https://arxiv.org/pdf/1902.00751.pdf)
Some numbers, tests conducted by Houlsby et al. CoLA, SSt, etc are customary benchmark datasets in NLP area.

Houlsby et al. (https://arxiv.org/pdf/1902.00751.pdf)51.pdf)
Another important aspect where adapters and their fusion play an important role is the infamous phenomena of Catastrophic Forgetting, which will be explained in the third section.
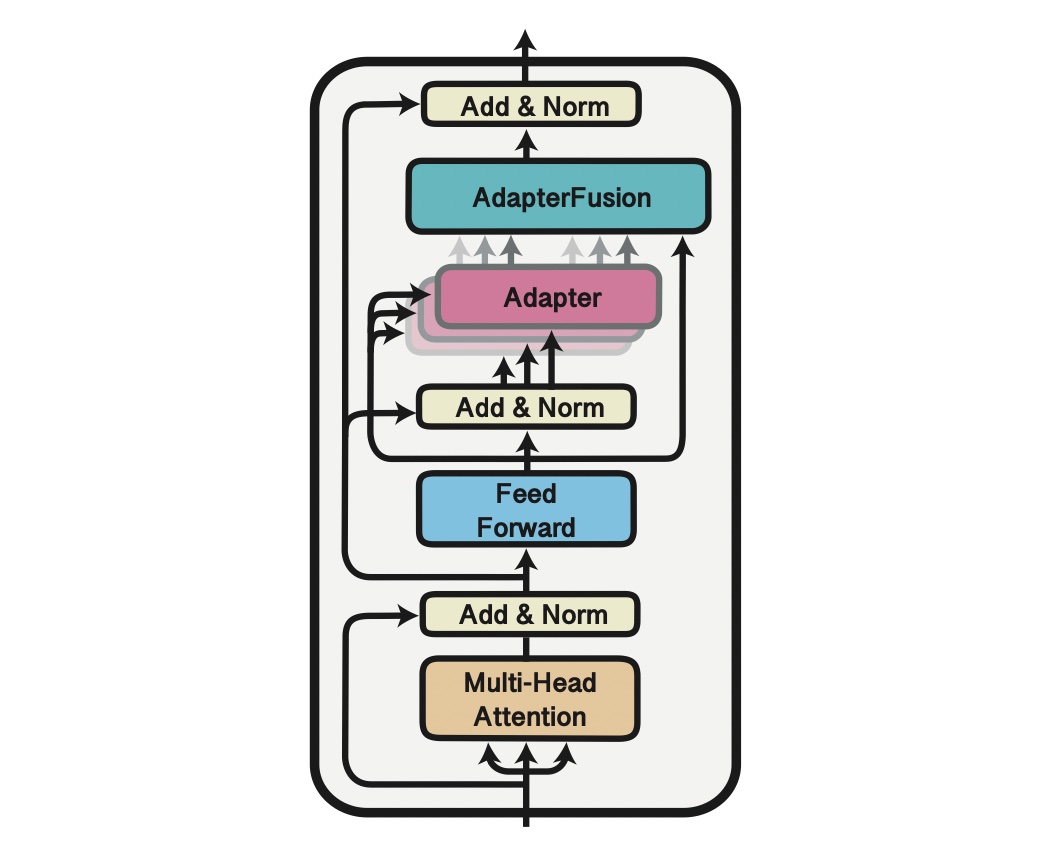
The idea of adapters in Transformers comes from Houlsby et al. (2019) in the paper „Parameter-Efficient Transfer Learning for NLP”. Originally, it consists of two small additional blocks inside the encoder layer in the Transformer architecture. During training we completely freeze the model’s parameters, leaving only adapters parameters to be trained.
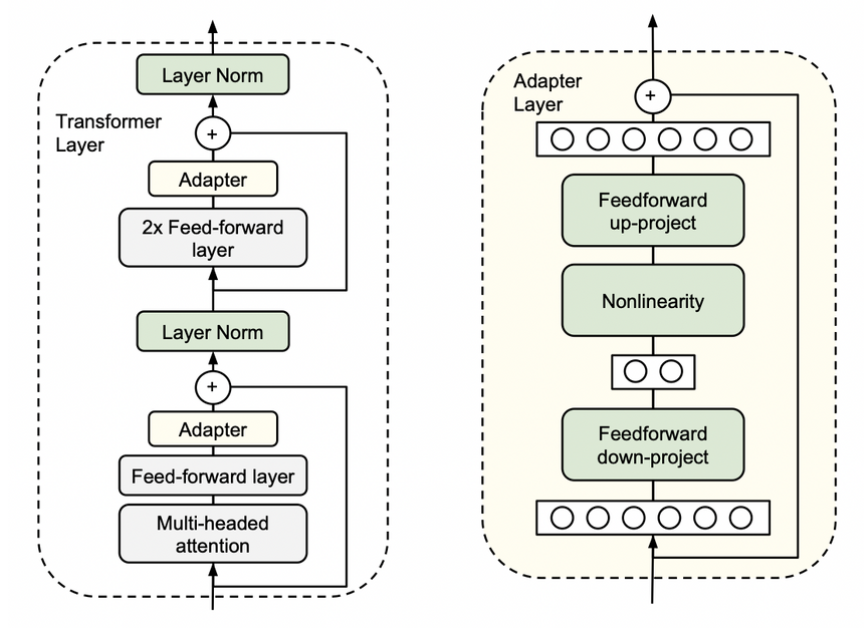
Houlsby et al. (https://arxiv.org/pdf/1902.00751.pdf)
The adapter is nothing more than another feature and information extractor with his „bottleneck” architecture. Processed data is projected to a lower dimension to filter only crucial information. After all, it is converted to the original size to match the model’s requirements. We call this configuration „Houlsby architecture” after the author. There are also different ideas with only one adapter layer, e.g., „Pfeiffer architecture,” which is lighter and the drop in performance is negligible.
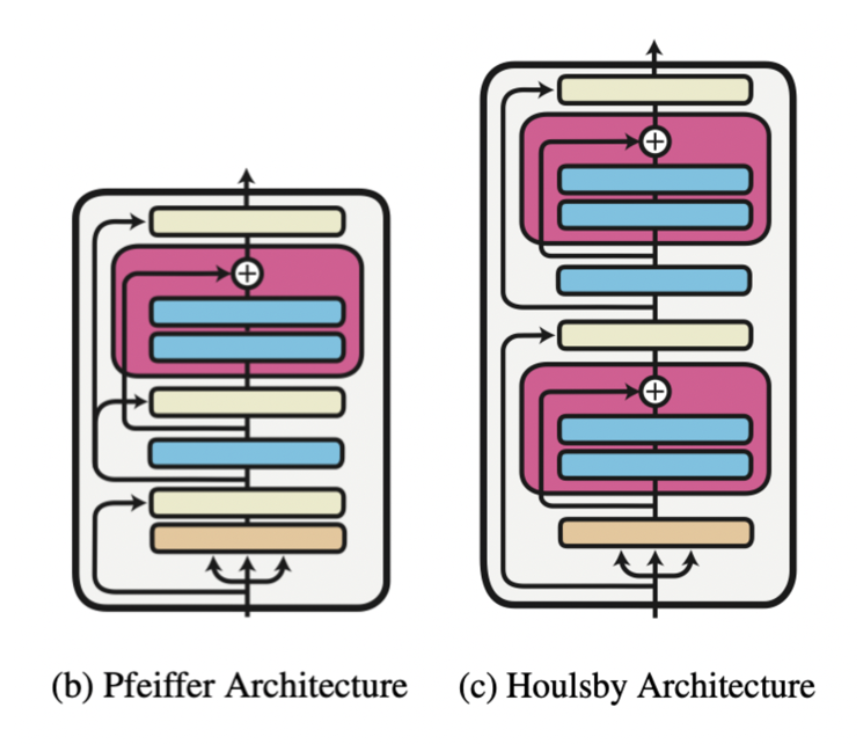
Pfeiffer et al. (https://arxiv.org/pdf/2005.00247.pdf)
Researchers and practitioners mostly use Houlsby architecture as it is based configuration and there is a hypothesis that lack of adapters in the last transformer layer is beneficial. Adapters in all encoder layers except the last one are encapsulated by frozen feed forward layers. It means they are separated from each other. Pfeiffer’s architecture in the last layers practically does not have an adapter as it is part of the prediction head. In contrast, Houlsby’s one has one adapter after a multi-head attention layer that is covered with a frozen feed forward layer above. Second is the extension of the prediction head.
The key idea is that an adapter works as an information extractor for a specific task, which will be crucial in the following section.
Once we know what adapters are, we can train a set of them each for individual tasks. The idea of fusion is to combine task-specific adapters with a single fusion layer that is similar to the attention layer. Both attention and fusion layers use the same equation and algorithm to calculate output.
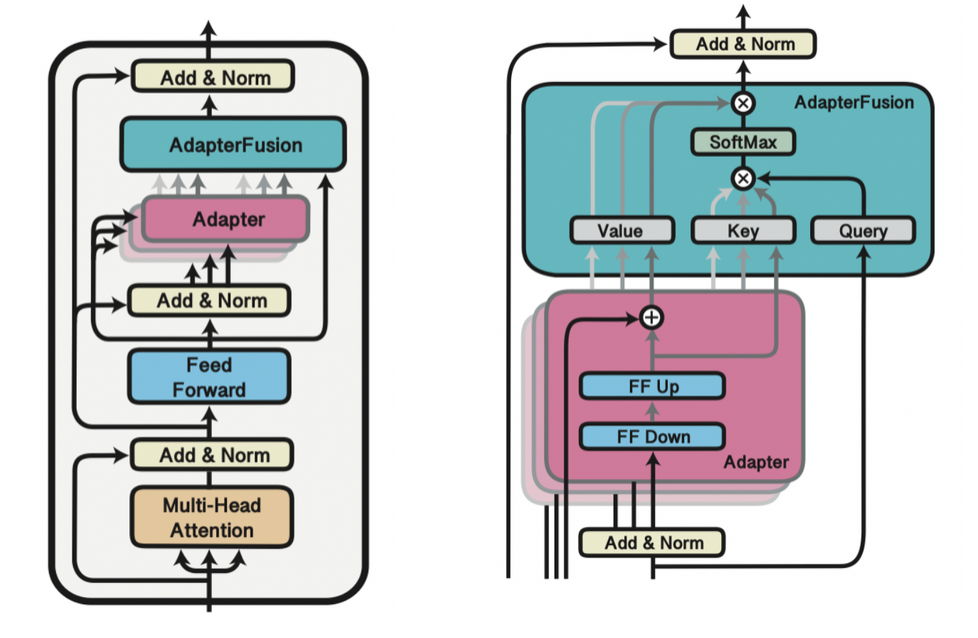
Pfeiffer et al. (https://arxiv.org/pdf/2005.00247.pdf)
This fusion layer learns to identify and activate the most useful adapter for a given input. The general rule is that adapters in lower layers are more generic, and thus are activated more often. In contrast, top-layer adapters are focused on details. Furthermore, Adapter Fusion extracts only information from adapters if they are beneficial for the specific task.
Adapter Fusion training can be divided into two stages.

Step 1. Freeze model’s parameters and train adapters – knowledge extraction
Step 2. Freeze model’s and adapters parameters then train fusion layers – knowledge composition
Continual aspect of learning focuses on situations where we have trained a model and, after some time, the new data with different distribution. In a fine-tuning regime, we would have to re-train our model with all the data gathered. It would not only be very time-consuming but also, as the model learns new patterns, the weights are overwritten. It leads to forgetting the previous knowledge. This phenomenon is called Catastrophic Forgetting.
Adapters help avoid this common pitfall of multi-task learning. New adapters learn knowledge for new tasks, and old ones do not have to be overwritten. Fusion combines adapters, learning which and when each adapter should be activated.
Sometimes we are forced to work in a regime of a small amount of data – a Few-Shot scenario. This is another aspect where adapters fits well thanks to its relatively small architecture. In the next section, we will see how they perform on a small dataset.
We are going to implement adapter fusion with the Bert model using Pytorch and the transformers library. [1]
We will download and load the CommitmentBank (De Marneffe et al., 2019) dataset.
from datasets import load_dataset
dataset = load_dataset("super_glue", "cb")
print(dataset.num_rows)
-> {'test': 250, 'train': 250, 'validation': 56}This dataset has 556 examples, each of which contains a premise and a hypothesis. The objective is to classify the relationships between them. Whether it is 'entailment’, 'contradiction’, or 'neutral’.
The first step is to encode data for the selected Bert model (bert-base-uncased from hugging face).
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
def encode_batch(batch):
"""Encodes a batch of input data using the model tokenizer."""
return tokenizer(
batch["premise"],
batch["hypothesis"],
max_length=180,
truncation=True,
padding="max_length")
# Encode the input data
dataset = dataset.map(encode_batch, batched=True)
# The transformers model expects the target class column to be named "labels"
dataset = dataset.rename_column("label", "labels")
# Transform to pytorch tensors and only output the required columns
dataset.set_format(type="torch", columns=["input_ids", "attention_mask", "labels"])After that, we can create an instance of Bert with the proper configuration and labels.
from transformers import BertConfig, BertModelWithHeads
# Preparing labels equivalent
id2label = {id: label for (id, label) in enumerate(dataset["train"].features["labels"].names)}
config = BertConfig.from_pretrained(
"bert-base-uncased",
id2label=id2label,
)
model = BertModelWithHeads.from_pretrained(
"bert-base-uncased",
config=config,
)Later, we can add adapters (we use pre-trained from adapterhub) without classification heads and activate them. All of them are in Houlsby configuration and were trained on different task-specific datasets:
nli – part of GLUE benchmark (https://gluebenchmark.com)
multinli – (https://cims.nyu.edu/~sbowman/multinli/)
On top of that, we add an adapter fusion layer and cover it with a randomly initialized classification head which we call „cb”.
from transformers.adapters.composition import Fuse
# Load the pre-trained adapters we want to fuse
model.load_adapter("nli/multinli@ukp", load_as="multinli", with_head=False)
model.load_adapter("sts/qqp@ukp", load_as="sts", with_head=False)
model.load_adapter("nli/qnli@ukp", load_as="nli", with_head=False)
# Add a fusion layer for all loaded adapters
model.add_adapter_fusion(Fuse("multinli", "qqp", "qnli"))
model.set_active_adapters(Fuse("multinli", "qqp", "qnli"))
# Add a classification head for our target task
model.add_classification_head("cb", num_labels=len(id2label))It is time to freeze the model and adapters parameters. Only fusion layers need to be trained.
# Unfreeze and activate fusion setup
adapter_setup = Fuse("multinli", "qqp", "qnli")
model.train_adapter_fusion(adapter_setup)The last step is to prepare the evaluation metric and the training part.
import numpy as np from transformers
import TrainingArguments, AdapterTrainer, EvalPrediction
training_args = TrainingArguments(
learning_rate=5e-5,
num_train_epochs=5,
per_device_train_batch_size=32,
per_device_eval_batch_size=32,
logging_steps=200,
output_dir="./training_output",
overwrite_output_dir=True,
# The next line is important to ensure the dataset labels are properly passed to the model
remove_unused_columns=False,
)
def compute_accuracy(p: EvalPrediction):
preds = np.argmax(p.predictions, axis=1)
return {"acc": (preds == p.label_ids).mean()}
trainer = AdapterTrainer(
model=model,
args=training_args,
train_dataset=dataset["train"],
eval_dataset=dataset["validation"],
compute_metrics=compute_accuracy,
)
# Train model
trainer.train()Then we can evaluate our model after fusion, reaching up to a 71% accuracy score!
print(trainer.evaluate())
-> {'eval_loss': 0.7297406792640686,
'eval_acc': 0.7142857142857143,
'eval_runtime': 1.1516,
'eval_samples_per_second': 48.628,
'eval_steps_per_second': 1.737,
'epoch': 5.0}As we have seen, Adapter Fusion is an interesting compact method of Transfer Learning. Reaching nearly SoTA results but with much less effort and time. In addition to this, they perform well in the Few-Shot and Continual Learning regimes and are able to face Catastrophic Forgetting problem.
Author: Beniamin Sereda

