

Natural Language Processing
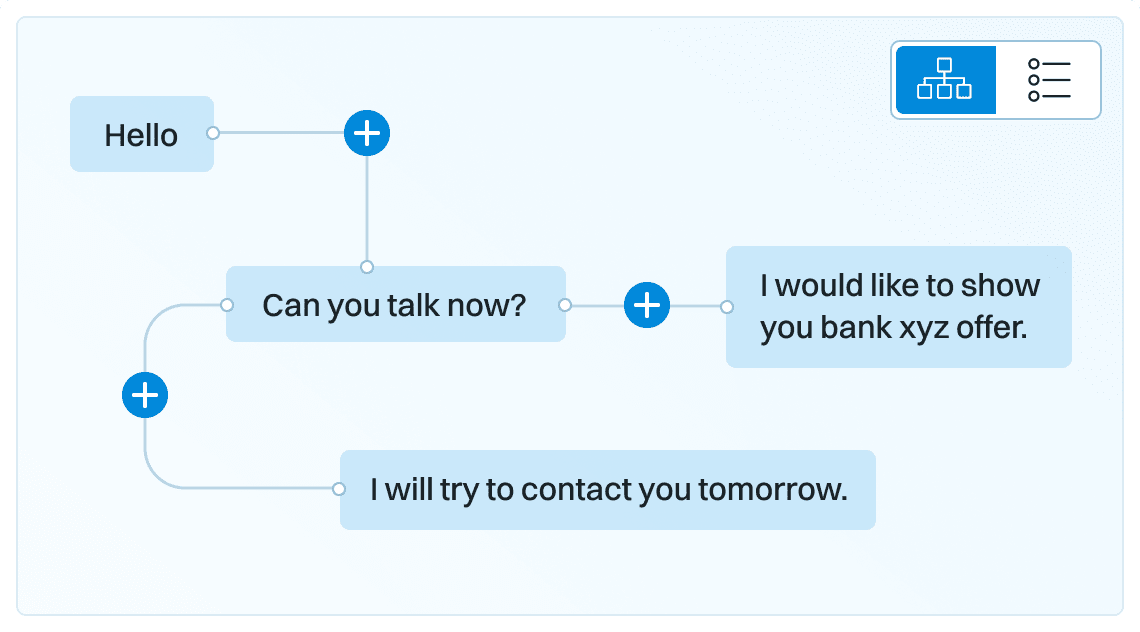
Generating paraphrases
Generating paraphrases

TRURL brings additional support for specialized analytical tasks:
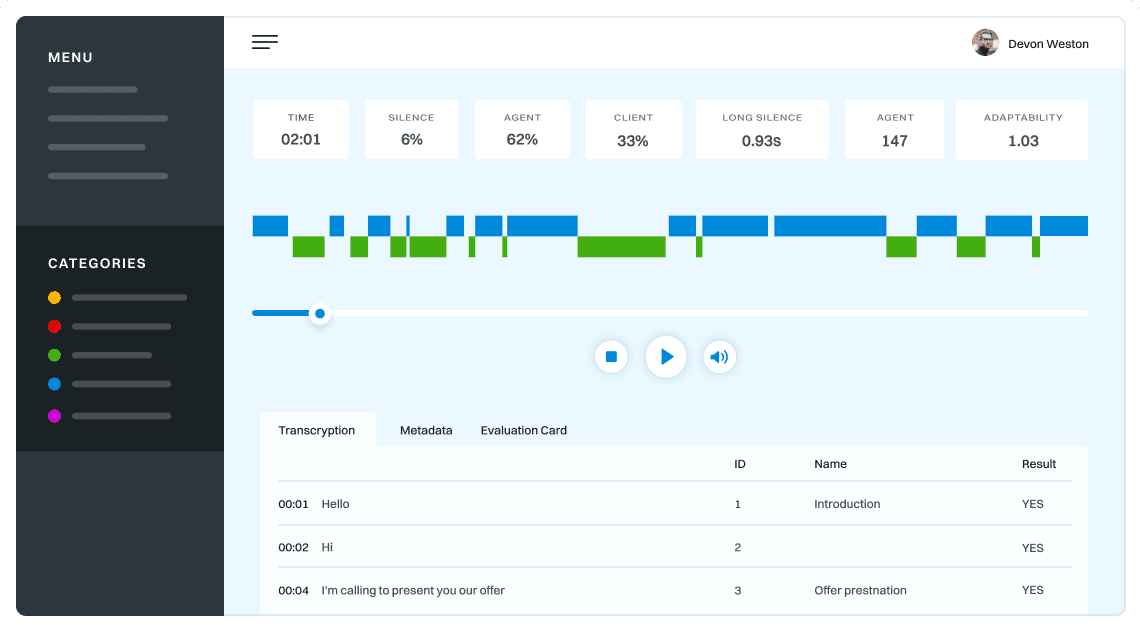
Dialog structure aggregation
Customer support quality control
Sales intelligence and assistance
TRURL can also be implemented effectively on-premise:
We will build a GPT model for you
Trained securely on your infrastructure
Trained on your dataset

Share

When developing an NLP solution it is often problematic to transfer the model to a new domain. The issue might be a lack of properly annotated dataset or one that is not big enough to provide full domain knowledge, even though you have a lot of audio recordings available. Annotating additional, large volumes of your data might be very costly and cost-inefficient, especially when dealing with multiple languages, since you’ll need separate teams for each one. However, you can make use of that data in an unsupervised learning manner – it is proven to greatly increase model comprehension on examples similar to those from pre-training phase. The recordings simply need to be properly formatted.
The rest of the article is available on the link below: https://colab.research.google.com/drive/1Uw7yV1iA2oBmnVPyRIQHmJXoSiER_yUG?usp=sharing
(NOTICE) In order to be able to use the notebook and send requests to our services, you have to upload a 'credentials.ini’ file to the runtime workspace (the main directory, next to sample_data folder). You can obtain one by getting in touch over at https://voicelab.ai/contact.
Author: Patryk Neubauer

