

Natural Language Processing
Generating paraphrases
Generating paraphrases

TRURL brings additional support for specialized analytical tasks:
Dialog structure aggregation
Customer support quality control
Sales intelligence and assistance
TRURL can also be implemented effectively on-premise:
We will build a GPT model for you
Trained securely on your infrastructure
Trained on your dataset

Share
Without a doubt, COVID-19 has had a great impact on today’s world. It has changed nearly all aspects of daily life and has become part and parcel of social discussion. Due to many COVID-19 restrictions, the majority of conversations have moved to social media, especially to Twitter which is one of the biggest social media platforms in the world. Since the opinions posted there highly influence society’s attitude towards COVID-19, it is important to understand Twitter users’ perspectives on the global pandemic. Unfortunately, the number of tweets posted on the Internet is enormous, thus an analysis performed by humans is impossible. Thankfully, for this purpose, one of the fundamental tasks in Natural Language Processing – sentiment analysis – can be performed which classifies text data into i.e. 3 categories (negative, neutral, positive).
Today, we would like to share with you some key insights on how we performed such sentiment analysis based on scraped Polish tweets related to COVID-19.
In the beginning, we had to scrape the relevant tweets from Twitter.
Since we were particularly interested in analyzing the pandemic situation in Poland, we downloaded tweets which:

were written in Polish,
were posted from the beginning of the pandemic (March 2020) until the beginning of the holidays (July 2021),
contain at least one word from the empirically created list of COVID-19 related keywords (such as “covid” or “vaccination” etc.)
With the following approach, we successfully managed to scrape more than 2 million tweets with their contents and variety of metadata such as:
the number of likes under a given tweet,
the number of replies under a given tweet,
the number of shares of a given tweet, etc.
However, for the purpose of training the model, we also had to obtain data with the previously labeled sentiment (negative, neutral, positive).
Unfortunately, there is currently no dataset that is publicly available containing Polish tweets about COVID-19. That is why we had to extend the publicly available Twitter dataset from CLARIN.SI repository with 100 personally labeled COVID-19 tweets in order to train a model on a sample of domain-specific texts.
Before starting the training process, the data preprocessing step was performed. It was especially important in our case since the Twitter data contains a lot of messy text such as reserved Twitter words (eg. RT – for retweets) and users’ mentions. With the use of the tweet-preprocessor library, we removed all of these unnecessary text parts that could become noise for a model.
Moreover, we replaced the links with the special token $URL$ so that each link is perceived by the model as the same one. It was particularly important since in the later phase we noticed that the information of link presence is valuable for the model predictions.
At the end of the preprocessing stage, we decided to replace the emoticons with their real meaning (eg. “:)” was changed to “happy” and “:(” was replaced by “sad” etc.).
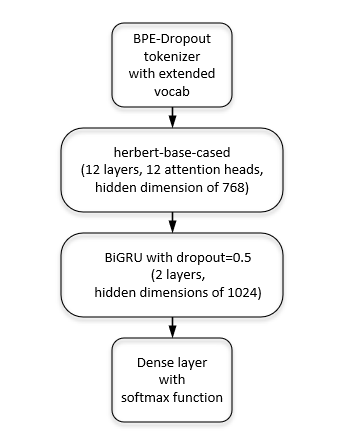
Having cleaned the data, we were able to build a model. We decided to base it on HerBERT (Polish version of BERT) since it receives state-of-the-art results in the area of text classification. We followed it with two layers of a bidirectional gated recurrent unit and a fully connected layer.
The BPE-Dropout tokenizer from HerBERT (which changes a text into tokens before passing input to HerBERT) was extended with additional COVID-19 tokens so that it would recognize (not separate) the basic coronavirus words.
| Metric | Score |
| F1-Score | 70.51% |
| Accuracy | 72.14% |
| Precision | 70.60% |
| Recall | 70.44% |
The model receives relatively good results even though Twitter data is often considered ambiguous when it comes to the sentiment label itself and ironic.
With the trained model, the sentiment for previously scraped COVID-19 tweets was predicted. This allowed us to perform a more detailed analysis, which was based not only on collected metadata (eg. likes, replies, retweets) but also on predicted sentiment.
When the weekly number of tweets for each sentiment is visualized over time, some negative “picks” can be observed
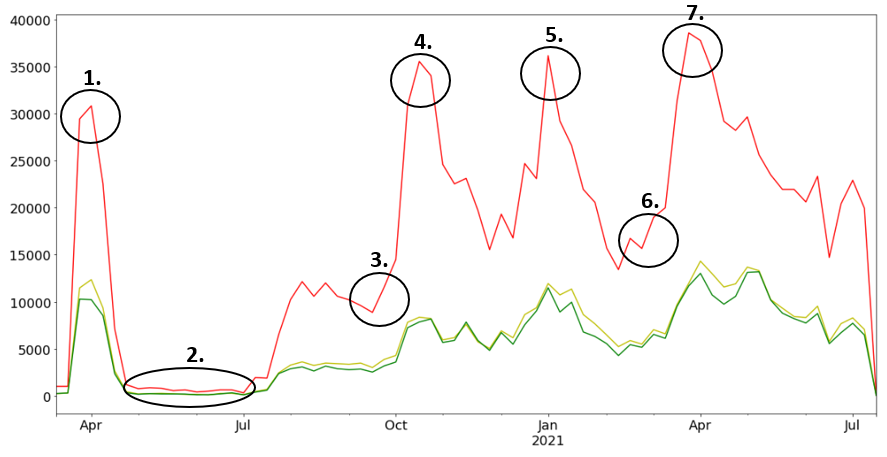
In the majority of cases, they are strictly correlated with important events/decisions in Poland such as:
Postponement of the presidential election
Presidential campaign
The beginning of the second wave of COVID-19
The return of hard lockdown restrictions
The beginning of vaccination in Poland
The beginning of the third wave of COVID-19
The daily record of infections (over 35,000 new cases)
When we decided to dive deeper into the content of negative Tweets, these were the most frequently used negative expressions:

Undoubtedly, they are slightly biased towards the keywords based on which we scraped the Tweets, but overall they give a good sense of topics covered in negative tweets i.e. politics and popular tags used in fake news activities.
Moreover, we were interested in analyzing who is the most frequently tagged account in these negative tweets. It came out that:
most frequently the politicians are blamed for their pandemic decisions
the accounts of the most popular television programs in Poland are a big part of COVID-19 discussions
Last but not least, we decided to analyze the Twitter accounts that influence society the most with their negative tweets (those that gain relatively the most likes/replies/retweets).
Unsurprisingly, these are politicians from the Polish opposition who are present at the top of the list.
To sum up, as we can all see, sentiment analysis accompanied by data analysis can give us interesting insight into the study community’s characteristics. It brings a lot of benefits and allows us to utilize huge amounts of text data effectively.
Share
Authors: Michał Laskowski, Filip Żarnecki

