

Natural Language Processing
Generating paraphrases
Generating paraphrases

TRURL brings additional support for specialized analytical tasks:
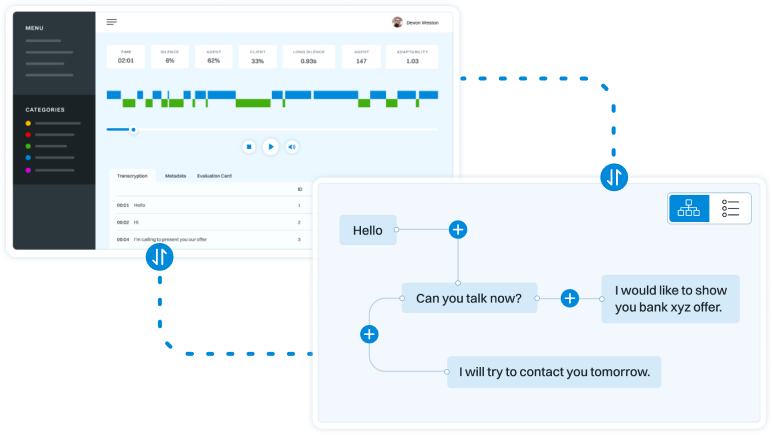
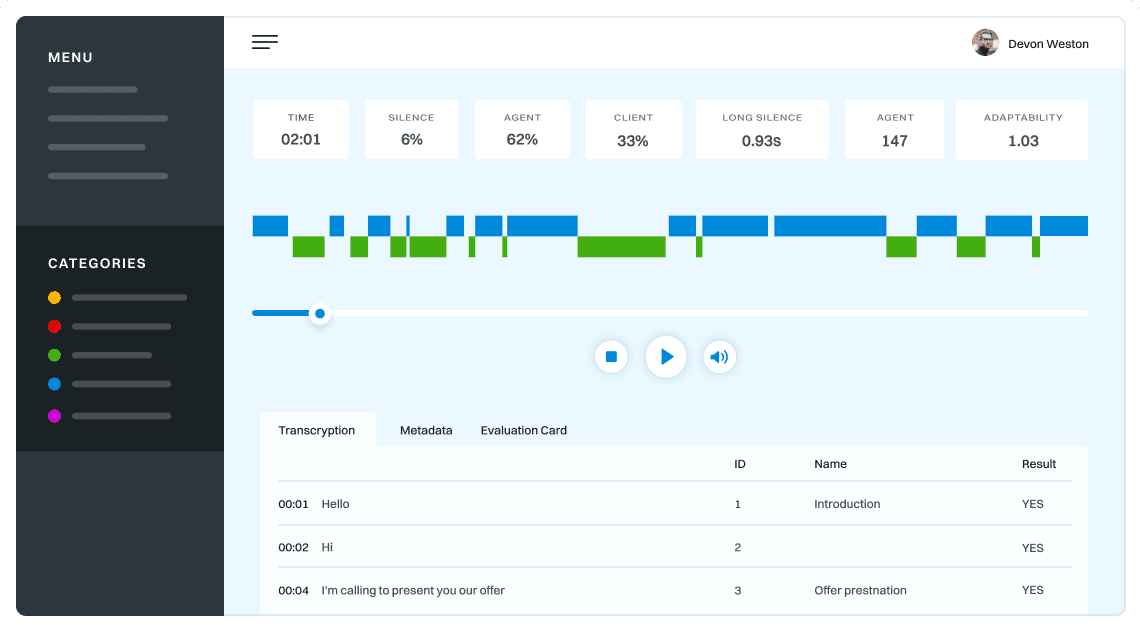
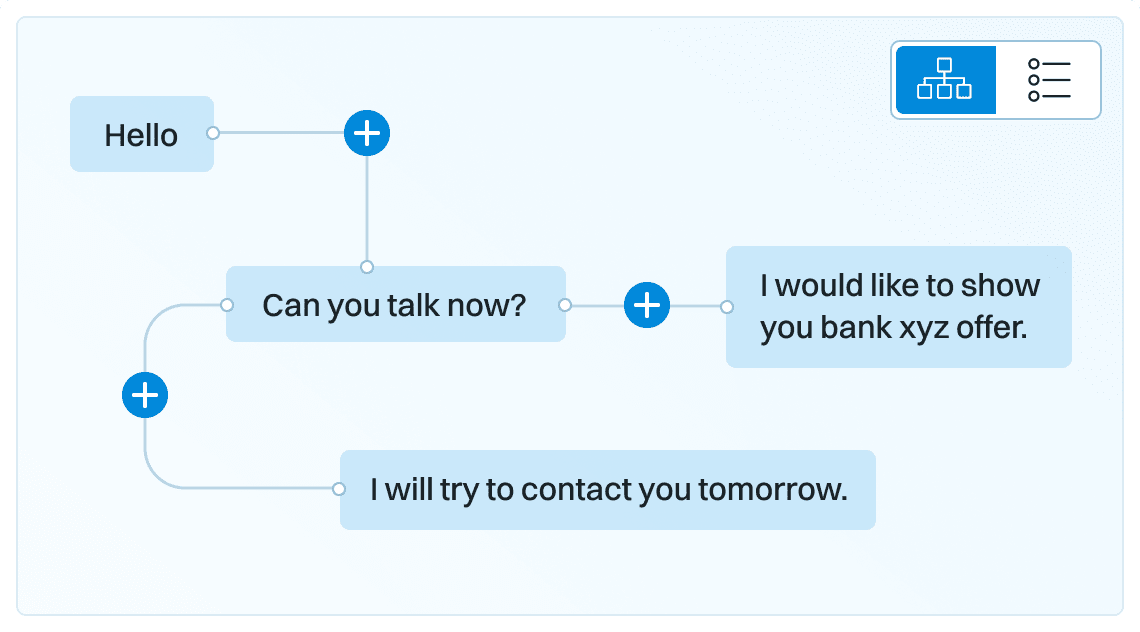
Dialog structure aggregation
Customer support quality control
Sales intelligence and assistance
TRURL can also be implemented effectively on-premise:
We will build a GPT model for you
Trained securely on your infrastructure
Trained on your dataset

Share

Knowing the customer is the success key of marketing. Enterprises collect more and more customer data. They do it openly or covertly. Sometimes, when asked about the quality of service, the company wants to discover what its client needs and adjust the offer accordingly.
It is related to high competition and the desire to match the offer in the best possible way.
The matter of customer data analysis is a very complex issue that concerns many industries. One of the types of data with high added value is complaints submitted for services or products.
The purpose of this task is to categorize company complaints using machine learning. Thanks to this, it will go to the appropriate department and be resolved faster.
Since the topic is very extensive we decided to analyze the complaints data from Consumer Financial Protection Bureau, a federal agency from the USA. They were downloaded from the official website, written in English, and include complaints about consumer financial products and services that the CFPB has sent to companies for response. The dataset contains more than 4 years of customer behavior in this area (the first data points are from 2017). In total, 28,864 anonymized complaints with their metadata were collected.
During the data analysis, only the isolated columns that were most important to the process were worked on: product, issue, subissue, narrative.
The complaints concerned the following products:

Credit reporting, credit repair services, or other personal consumer reports (19609)
Debt collection (4694)
Credit card or prepaid card (2790)
Checking or savings account (1692)
Mortgage (79)
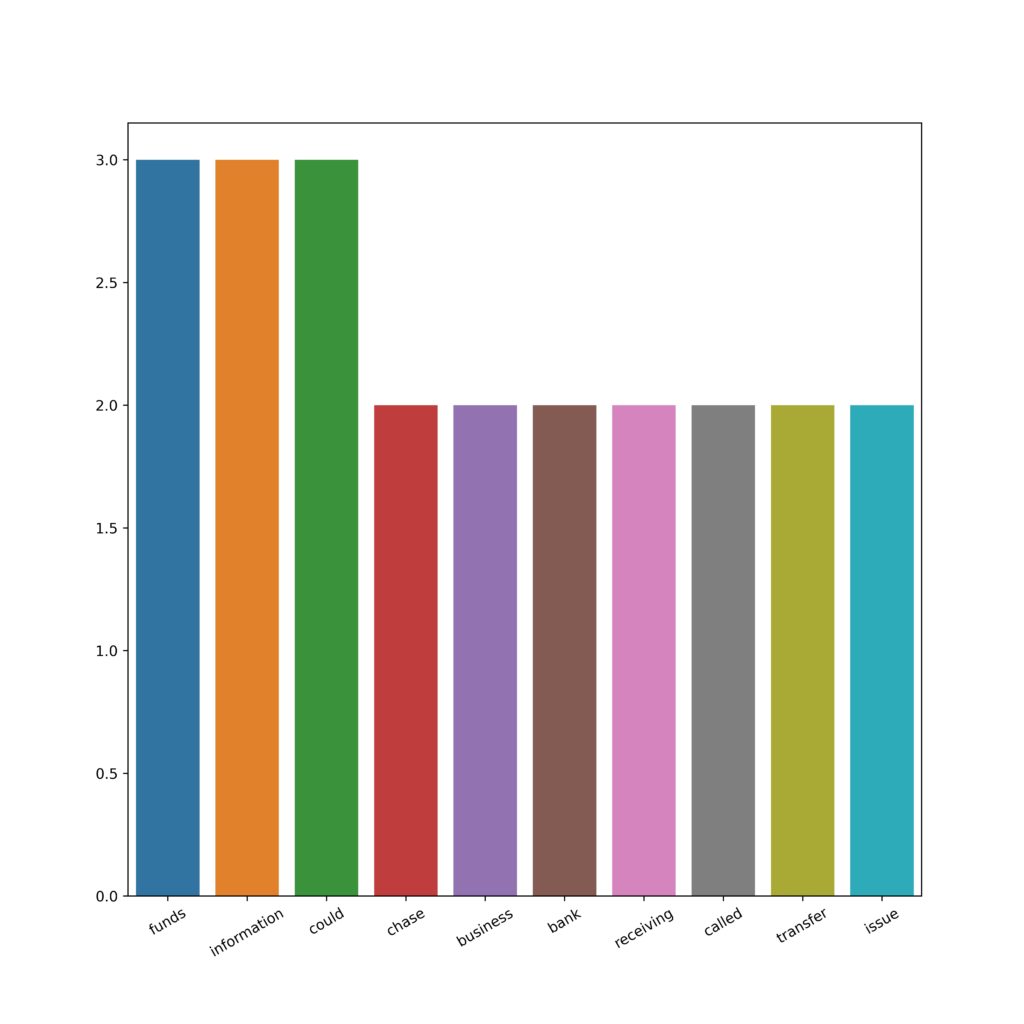
As part of data processing, the NLTK library was used. Dataset was tokenized and stopwords, numbers, and missing data were removed. Most of the top 20 tokens are what can be considered a stop word.
Also, the frequency analysis was performed. The most common words are ex.: account, report, credit, verified.
The main categories of the product were also renamed to make the names easy to type.
Mortgage and loans were combined because of the small frequency. Also, a set of information considering the complaint was joined together to have full information about a complaint. An example one is as follows:
Hello This complaint is against the three credit reporting companies. XXXX, XXXX XXXX and equifax. I noticed some discrepencies on my credit report so I put a credit freeze with XXXX.on XX/XX/2019. I then notified the three credit agencies previously stated with a writtent letter dated XX/XX/2019 requesting them to verifiy certain accounts showing on my report They were a Bankruptcy and a bank account from XXXX XXXX XXXX.
As the very first step to modeling vectorizing with TF-IDF (with max_features= 5000000) matrix was introduced. Also, the data was transformed by CountVectorizer as the second experiment. Lemmatization using WordNetLemmatizer was performed.
Before actual modeling, the matrix was divided into a training set (80%) and a testing set (20%). The product remained the target variable.
| product | narrative | |
| 0 | retail_banking | wife wired money personal account joint chase … |
| 1 | debt_collection | today individual sheriff department delivered … |
| 2 | credit_reporting | hello complaint three credit reporting company… |
The following types of models were tested:
Random Forest,
Decision Tree,
KNN,
Gradient Boosting
At first with default parameters, then with a few parameter selections.
The best result was achieved using Decision Tree with Count Vectorizer:
Accuracy: 94.5%
Precision: 95.4%
Recall: 75.9%
F1: 79.8%
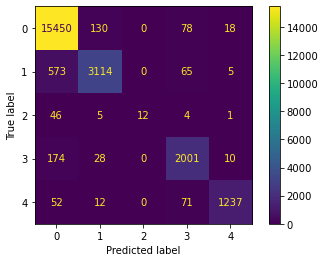
Also, due to imbalanced classes SMOTE was introduced. All models gave similar results between training and testing sets, which would mean that they didn’t overfit the data.
The second closest from the best was KNN:
Accuracy: 87.7%
Precision: 67.7%
Recall: 60.9%
F1: 63.8%
It is worth noting that one of the greater limitations of this task is the amount of data, or rather the number of variables, that is created for the text. In the case of models whose quality can be improved by searching for hyperparameters, these are already one-hour processes. Another point is that this is typical of a text analysis case.
The above task proves that free text machine learning can be very beneficial for the enterprise. The ability to automatically classify incoming documents saves a lot of money on the human factor. The models that were developed as first attempts are decent.
Share
Author: Karolina Wadowska

